Thema
- #Relationales Datenmodellieren
- #Logisches Datenmodellieren
- #Normalisierung
Erstellt: 2024-04-09
Erstellt: 2024-04-09 15:32
Übung zum Lernen und Durchführen der logischen Datenmodellierung
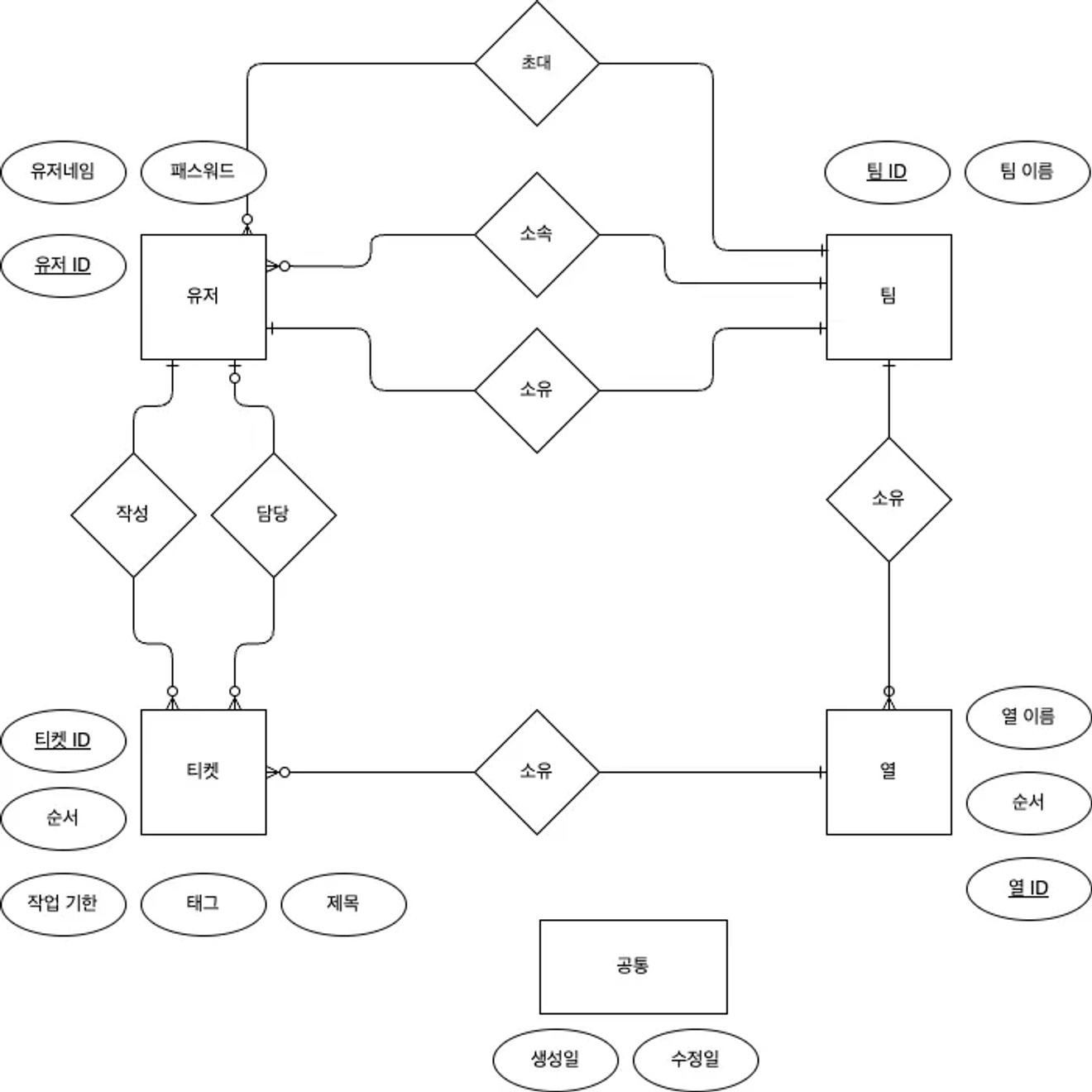
Konzeptionelles Datenmodell-ERD
Zuerst durchläuft man den Prozess der konzeptionellen Datenmodellierung und führt dann mit diesem ERD die logische Datenmodellierung durch.
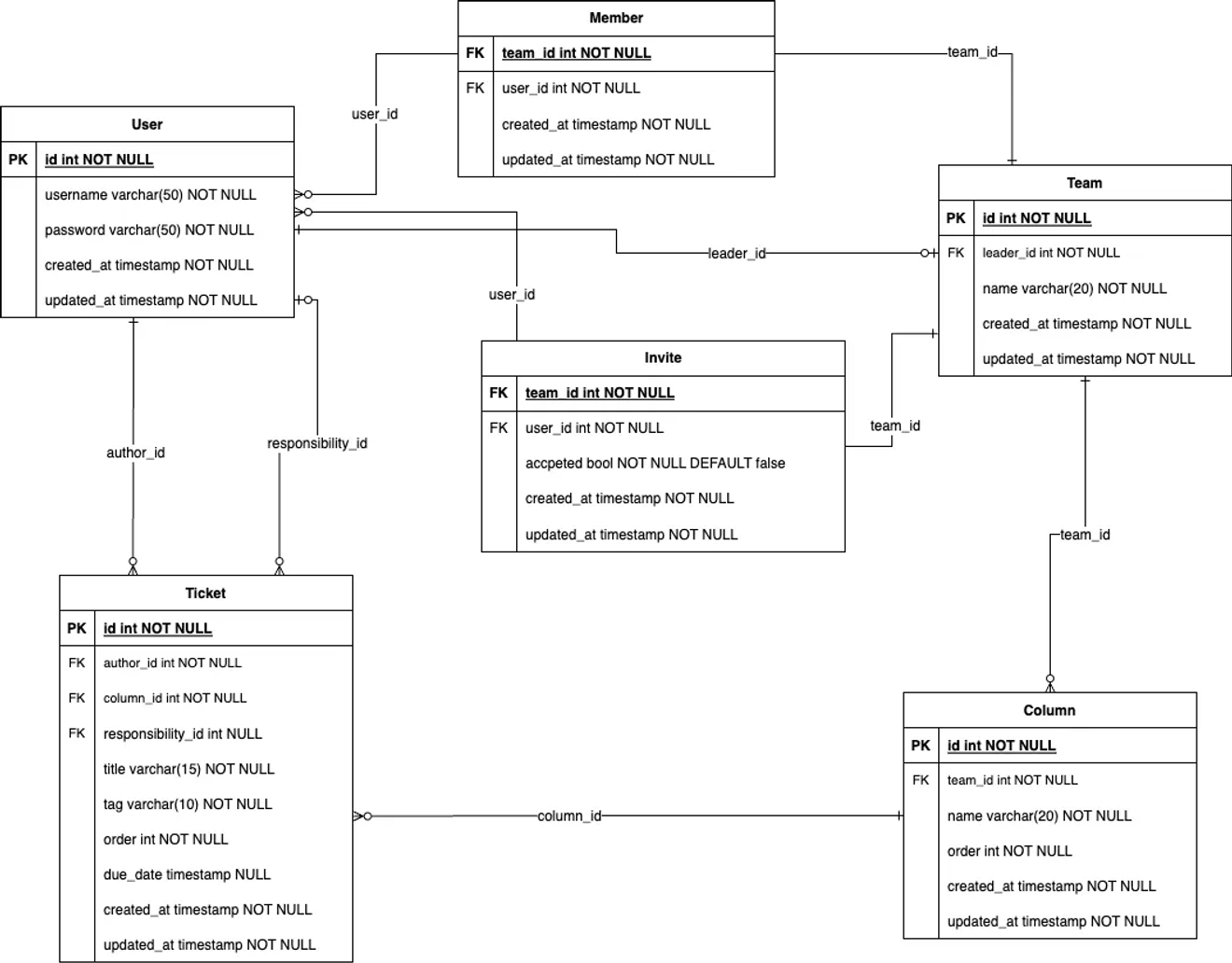
Logisches Datenmodell-ERD
Eine Herausforderung war es, die Beziehung zwischen beiden Tabellen anhand der Mapping-Tabelle zu betrachten.
Das konzeptionelle Datenmodell ERD wird in eine Tabellenform umgewandelt und anschließend normalisiert.
Die Normalisierungsschritte müssen sequenziell durchgeführt werden. Betrachtet man das obige ERD, so ist die 1. Normalform erfüllt.
Um die 2. Normalform zu erfüllen, wird aus dem Ticket-Tabellenfeld Tag eine Tabelle erstellt und der Primärschlüssel dieses Tags als Fremdschlüssel verwendet.
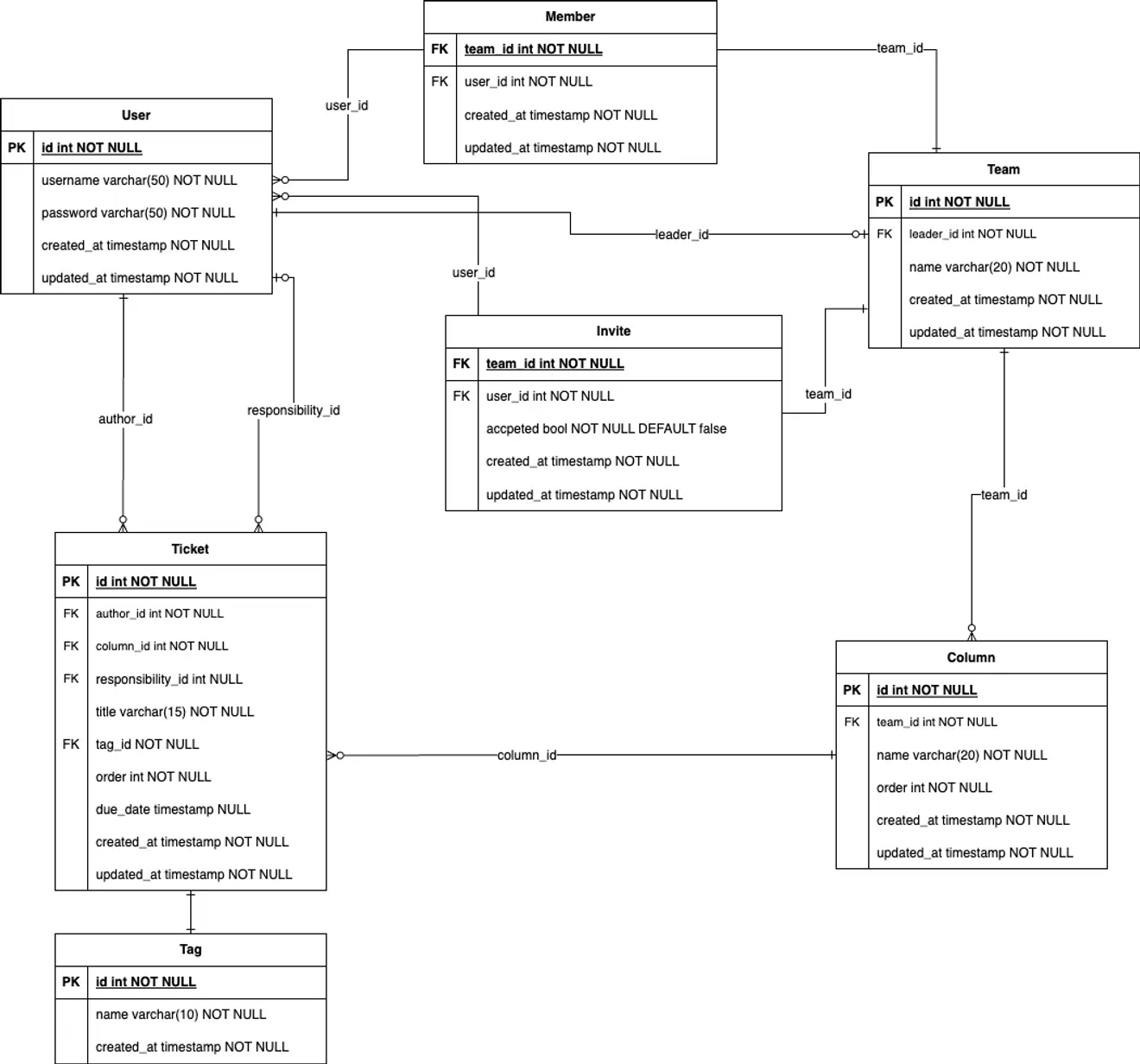
Normalisierungsprozess
Nun muss geprüft werden, ob die 3. Normalform erfüllt ist. Da mir das Konzept noch nicht ganz klar ist, finde ich das schwierig.
Ich bin mir nicht sicher, ob die author_id und responsibility_id Spalten der Ticket-Tabelle in eine separate Tabelle ausgelagert werden sollten. Da es keine N:M-Beziehung ist und es sich um einen Fremdschlüssel handelt, habe ich mich entschieden, dies zu ignorieren.
April 28, 2024
May 8, 2024
July 17, 2024
February 6, 2025
March 29, 2024
May 12, 2024
Kommentare0