Tema
- #Modelado de Datos Lógicos
- #Base de Datos
- #Modelado de Datos Relacional
Creado: 2024-04-09
Creado: 2024-04-09 12:21
En comparación con el análisis de requisitos y el modelado de datos conceptual, el modelado de datos lógico es un proceso más mecánico.
El proceso se centra principalmente en la transformación del diagrama ERD, que es el producto del modelado de datos conceptual, en un paradigma de base de datos relacional, basándose en las reglas de mapeo (Mapping Rule).
Es más conveniente representar primero las tablas que no tienen FK.
En una relación 1:1, se examina la relación de dependencia entre las dos tablas y se configura la FK.
Se puede ver como una tabla padre y una tabla hija.
En una relación 1:N, dado que 1 es referenciado por N, se configura la FK en N.
Para manejar una relación N:M en una base de datos relacional, se crea una tabla intermedia (también llamada tabla de mapeo o tabla de conexión) para expresarla.
En este caso, es importante expresar la cardinalidad y la opcionalidad de ambas tablas referenciadas en base a la tabla de mapeo.
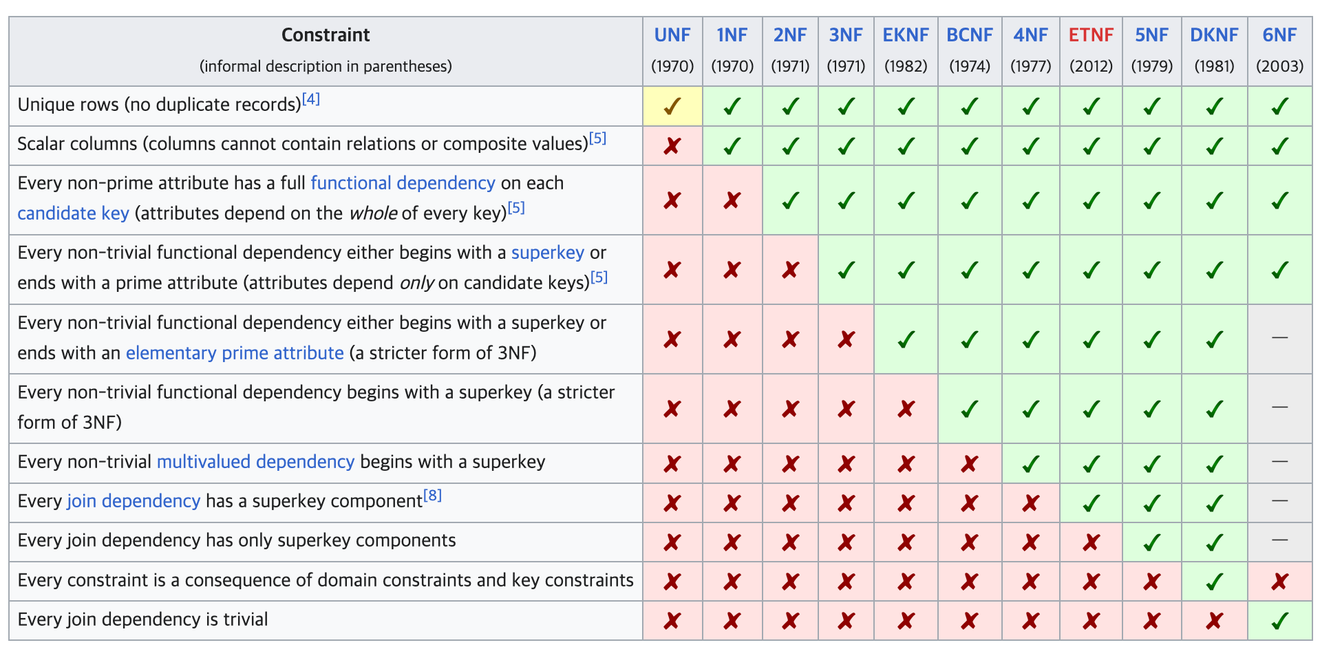
Wikipedia - Normalización de Bases de Datos
Es el proceso de convertir una tabla no refinada en una tabla adecuada para una base de datos relacional.
El proceso de normalización utilizado en la industria llega hasta la tercera forma normal, mientras que las formas normales posteriores se utilizan principalmente en el ámbito académico.
La normalización debe llevarse a cabo secuencialmente, un paso a la vez.
Si revisamos el principio fundamental de la primera forma normal, aunque es difícil de entender, simplemente significa que cada columna debe tener un solo valor.
Si hay varios valores dentro de una columna, es decir, si no es atómico, puede ser difícil realizar una unión con una instrucción SQL y puede causar varios problemas.
Si existen valores duplicados en las filas de una tabla, se busca la columna de la que depende dicha fila y se separa.
La expresión dependencia transitiva es muy difícil de entender. Según mi comprensión, si hay uno o más valores en una tabla específica que implícitamente significan el identificador de otra tabla (excluyendo FK, por supuesto), parece que eso se llama dependencia transitiva.
3 de abril de 2024
6 de febrero de 2025
29 de marzo de 2024
28 de abril de 2024
17 de julio de 2024
7 de septiembre de 2024
Comentarios0