Tema
- #Base de Datos
- #Modelado de Datos Físico
- #Modelado de Datos Relacional
Creado: 2024-04-09
Creado: 2024-04-09 23:01
Si el modelado de datos lógico consistía en crear las tablas ideales adecuadas para una base de datos relacional, el modelado de datos físico incluye la creación de tablas de uso real a partir de tablas ideales, y se centra en la mejora del rendimiento y la optimización, como la planificación eficiente del uso del espacio de almacenamiento, el diseño de particiones de objetos y el diseño de índices óptimos.
El método para encontrar consultas lentas (slow query) que causan cuellos de botella durante la operación del servicio varía según el tipo de DBMS, yconsultas lentas (slow query)debe buscarse mediante una búsqueda con la palabra clave.
Caché (Cache)
Si el problema de rendimiento no se resuelve con los métodos anteriores, se realiza una operación llamada desnormalización o denormalización.
Se trata de modificar la estructura de la tabla.
La normalización es como renunciar al rendimiento de lectura para facilitar las operaciones de escritura. Si se normaliza, debe escribirse una consulta que una los datos de varias tablas divididas.
Sin embargo, la normalización no siempre reduce el rendimiento, por lo que debe comprender y verificar correctamente el problema antes de realizar la desnormalización.
El siguiente enlace es un buen artículo que trata sobre ladesnormalizaciónque se tratará más adelante.
Lo primero que debe saber es que la desnormalización debe realizarse después de la normalización. Una tabla desnormalizada desde el principio no siempre es buena.
Por ahora, no es un conocimiento que necesite urgentemente, así que solo lo mencionaremos.
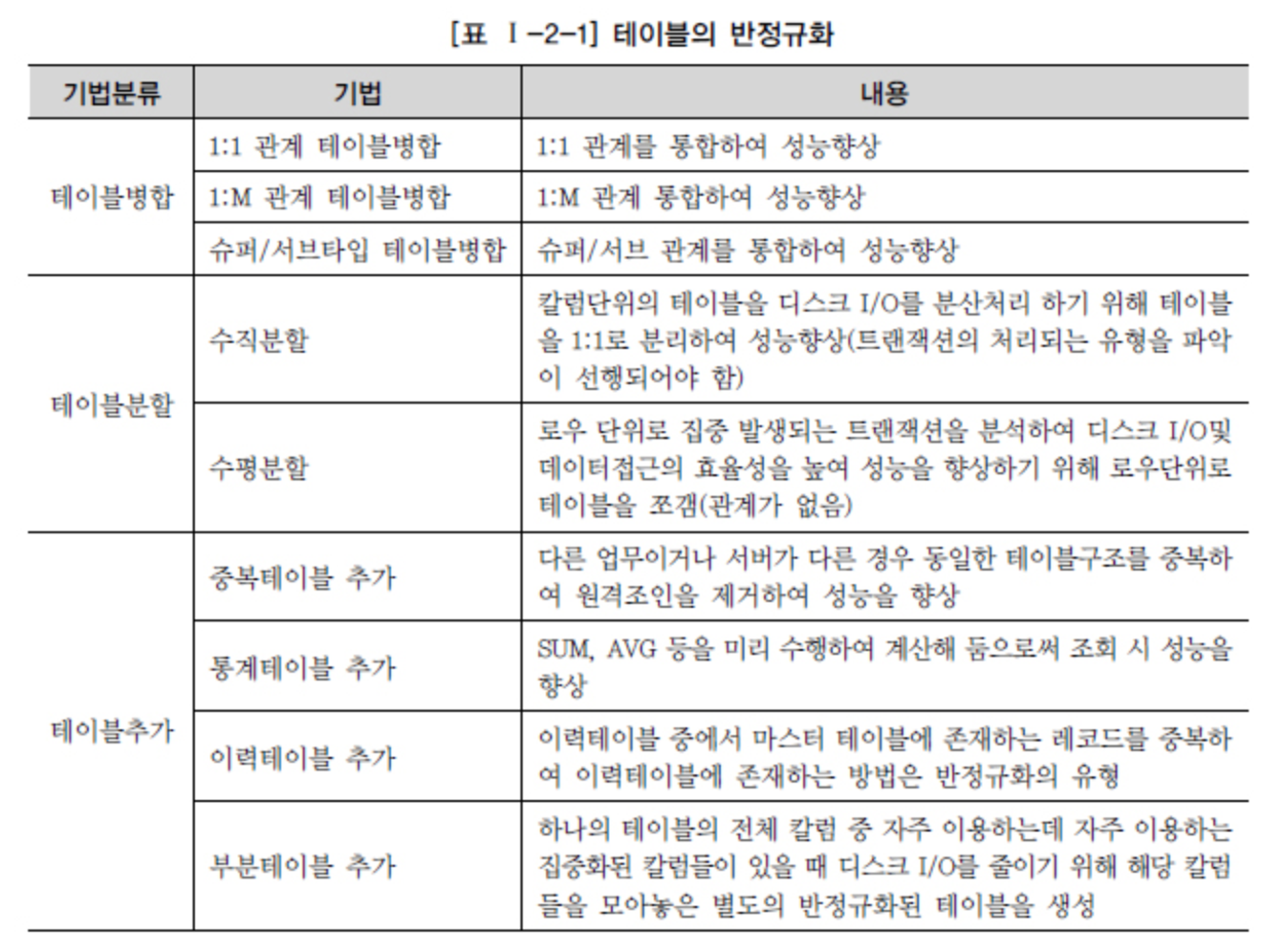
Fuente - DataOnAir - Desnormalización y rendimiento
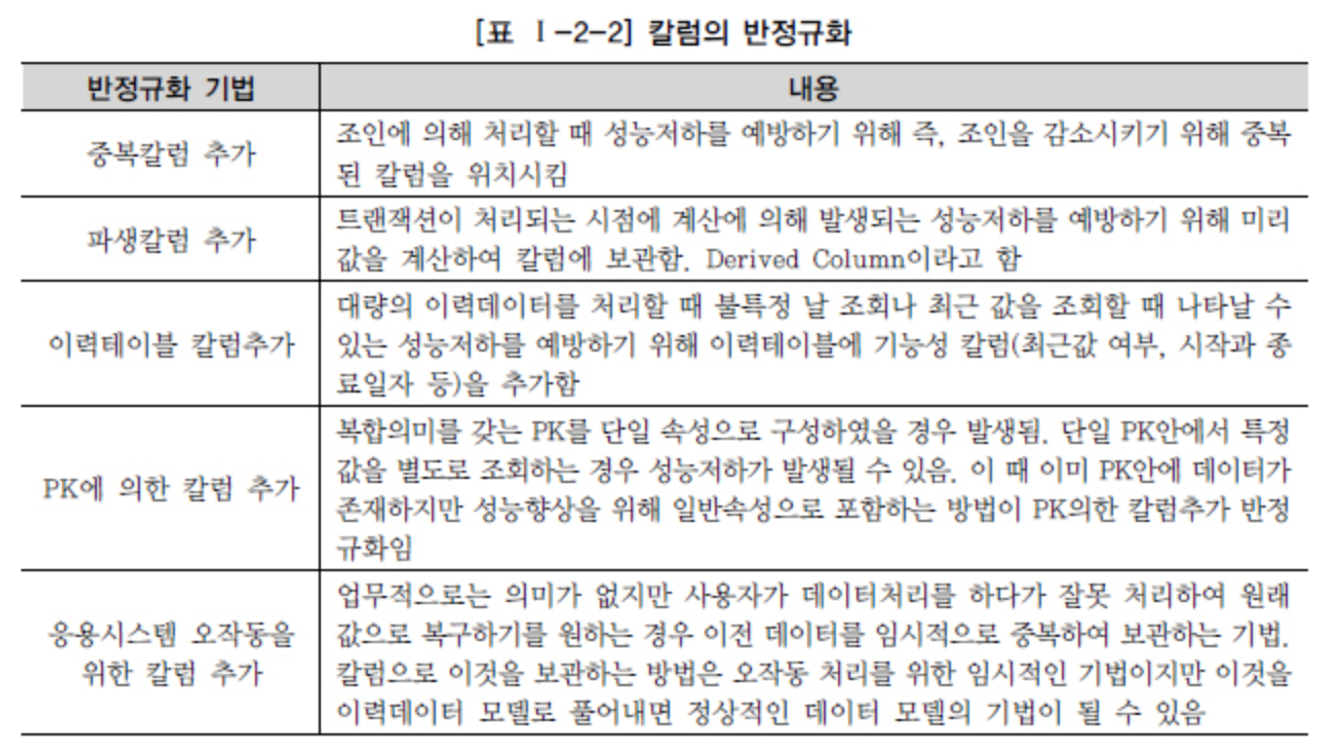
Fuente DataOnAir - Desnormalización y rendimiento

Fuente - DataOnAir - Desnormalización y rendimiento
25 de abril de 2024
25 de abril de 2024
28 de abril de 2024
3 de abril de 2024
29 de noviembre de 2024
13 de noviembre de 2024
Comentarios0