Sujet
- #Modélisation relationnelle des données
- #Modélisation logique des données
- #Base de données
Création: 2024-04-09
Création: 2024-04-09 12:21
Contrairement à l’analyse des exigences et à la modélisation des données conceptuelles, la modélisation des données logiques est une procédure plus mécanique.
Le processus principal consiste à convertir le diagramme ERD, qui est le résultat de la modélisation des données conceptuelles, en un modèle adapté au paradigme de base de données relationnelle en fonction des règles de mappage (Mapping Rule).
Il est préférable de commencer par représenter en priorité les tables sans FK.
Dans une relation 1 : 1, la dépendance entre les deux tables est examinée et la FK est définie.
On peut considérer qu’il s’agit d’une table parent et d’une table enfant.
Dans une relation 1 : N, puisque 1 est référencé par N, la FK est définie sur N.
Pour traiter une relation N : M dans une base de données relationnelle, une table intermédiaire (également appelée table de mappage ou table de liaison) est créée et représentée.
Dans ce cas, il est important de représenter la cardinalité et l’optionalité des deux tables référencées par la table de mappage.
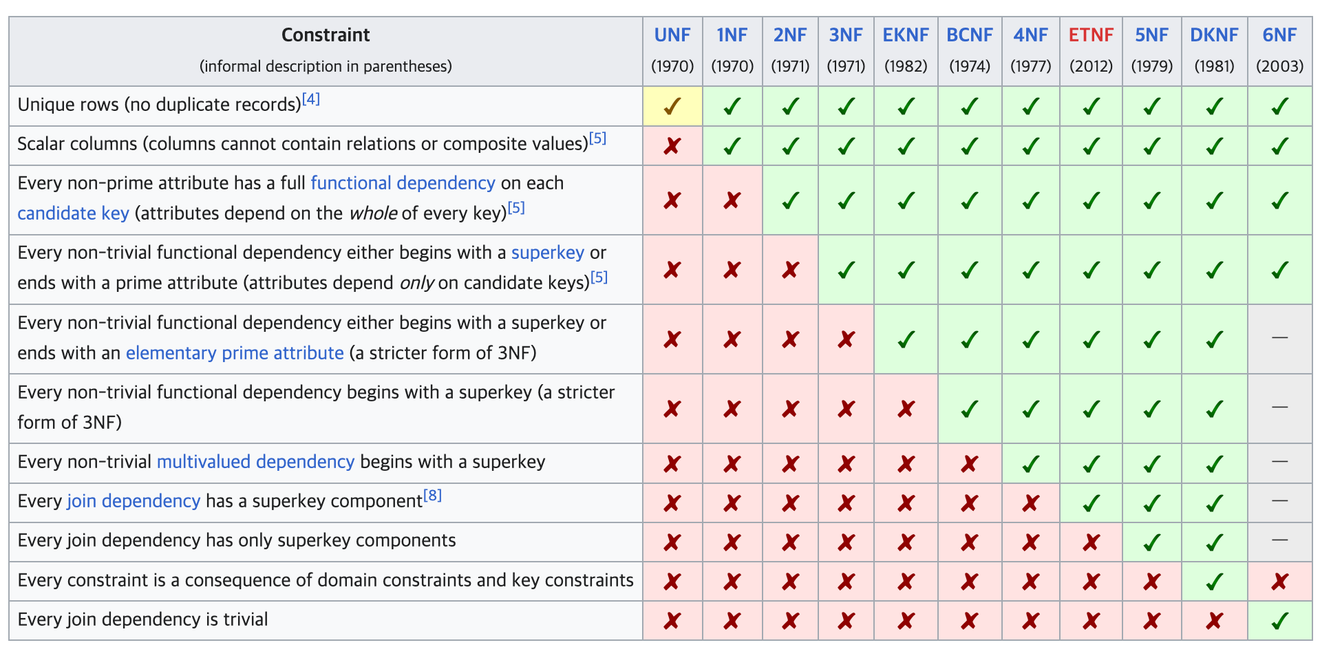
Wikipedia - Normalisation de base de données
Il s’agit du processus de transformation d’une table non raffinée en une table adaptée à une base de données relationnelle.
Dans le secteur industriel, le processus de normalisation s’arrête à la 3e forme normale, les formes normales suivantes étant principalement utilisées dans le domaine académique.
La normalisation doit être effectuée séquentiellement, étape par étape.
Si l’on examine le principe fondamental de la 1re forme normale, il est difficile de comprendre ce que cela signifie, mais cela signifie simplement que chaque colonne doit contenir une seule valeur.
Si plusieurs valeurs sont contenues dans une seule colonne, c’est-à-dire si elle n’est pas atomique, il peut être difficile de faire une jointure avec une instruction SQL et cela peut entraîner divers problèmes.
Si des valeurs en double existent dans les lignes d’une table, la colonne dont dépend cette ligne est trouvée et séparée.
L’expression « dépendance transitive » est très difficile à comprendre. D’après ma compréhension, si une table donnée contient une ou plusieurs valeurs qui impliquent implicitement l’identifiant d’une autre table (à l’exclusion de la FK bien sûr), cela semble être considéré comme une dépendance transitive.
February 6, 2025
March 29, 2024
April 28, 2024
July 17, 2024
April 3, 2024
April 28, 2024
Commentaires0