Sujet
- #Normalisation
- #Modélisation des données logiques
- #Modélisation des données relationnelles
Création: 2024-04-09
Création: 2024-04-09 15:32
Exercice d'apprentissage et de pratique de la modélisation de données logique
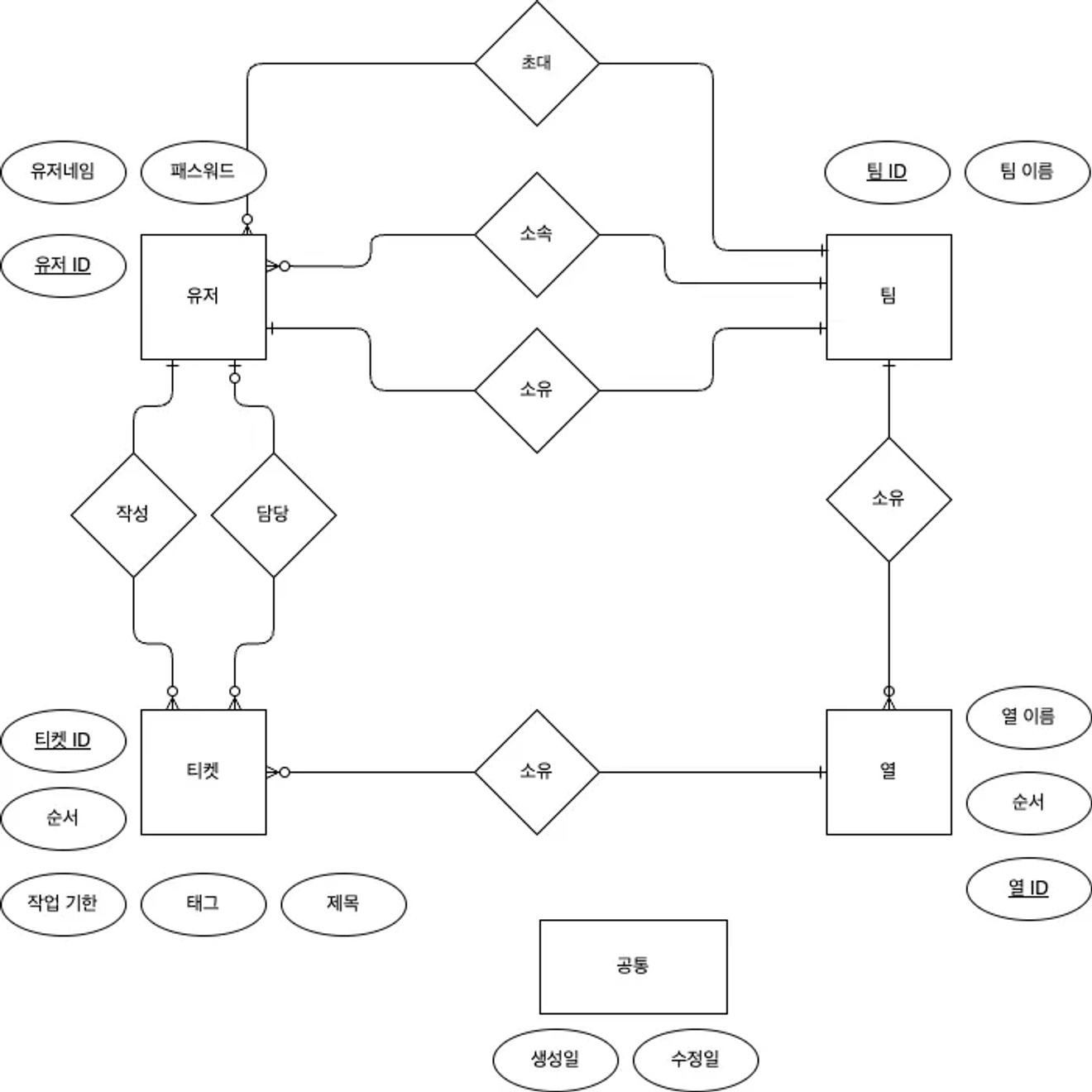
Diagramme ERD de la modélisation conceptuelle des données
Nous commençons par le processus de modélisation de données conceptuelle, et nous effectuons la modélisation de données logique en utilisant cet ERD.
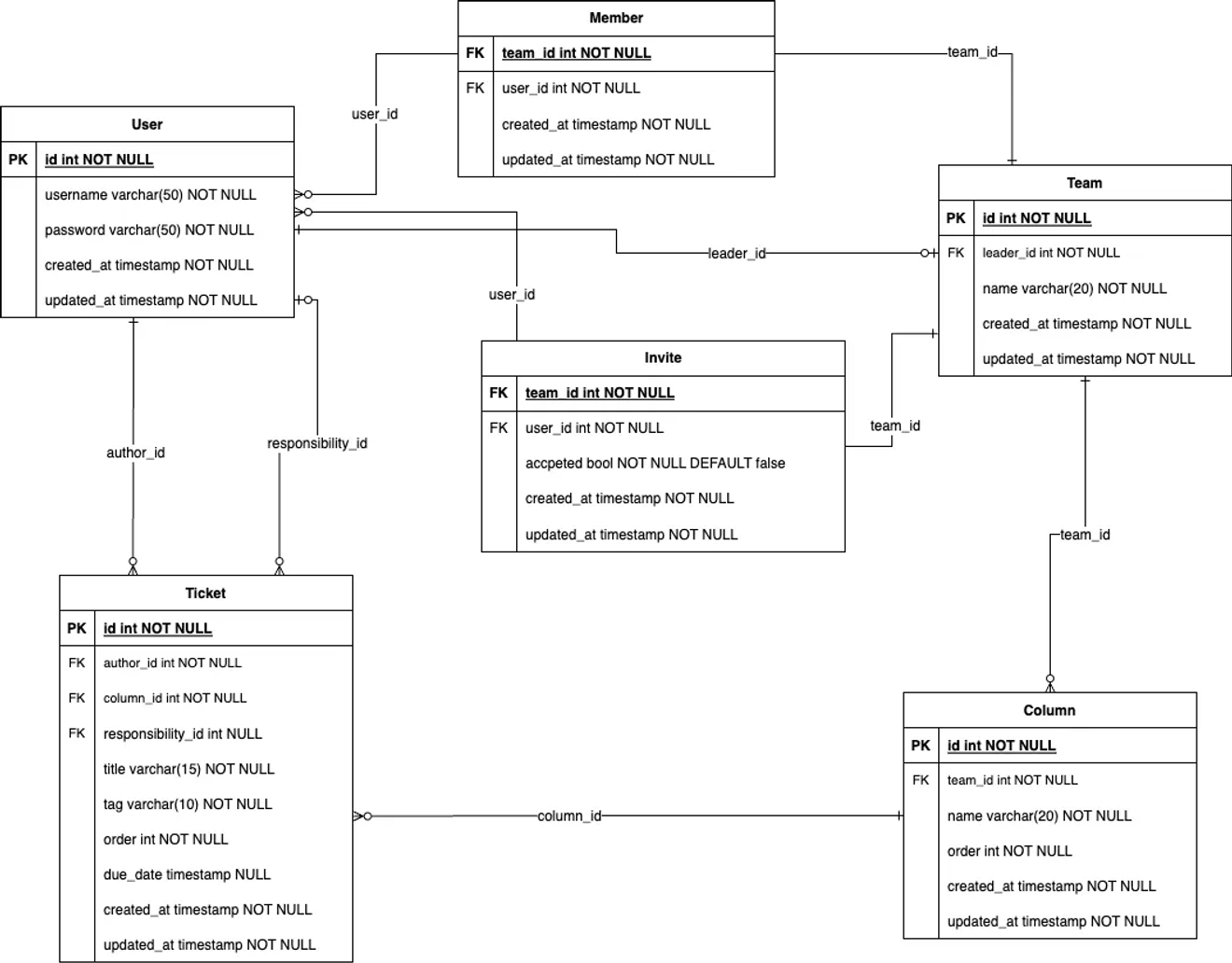
Diagramme ERD de la modélisation logique des données
Ce qui était un peu difficile, c'était de devoir penser à la relation entre les deux tables en se basant sur la table de mappage.
Après avoir converti l'ERD de modélisation de données conceptuelle en format table, nous effectuons la normalisation.
Les étapes de normalisation doivent être effectuées séquentiellement. En examinant l'ERD ci-dessus, nous pouvons constater qu'il satisfait à la 1ère forme normale.
Pour satisfaire à la 2ème forme normale, nous créons une table pour Tag dans la table Ticket, et nous utilisons la clé primaire de cette étiquette comme clé étrangère.
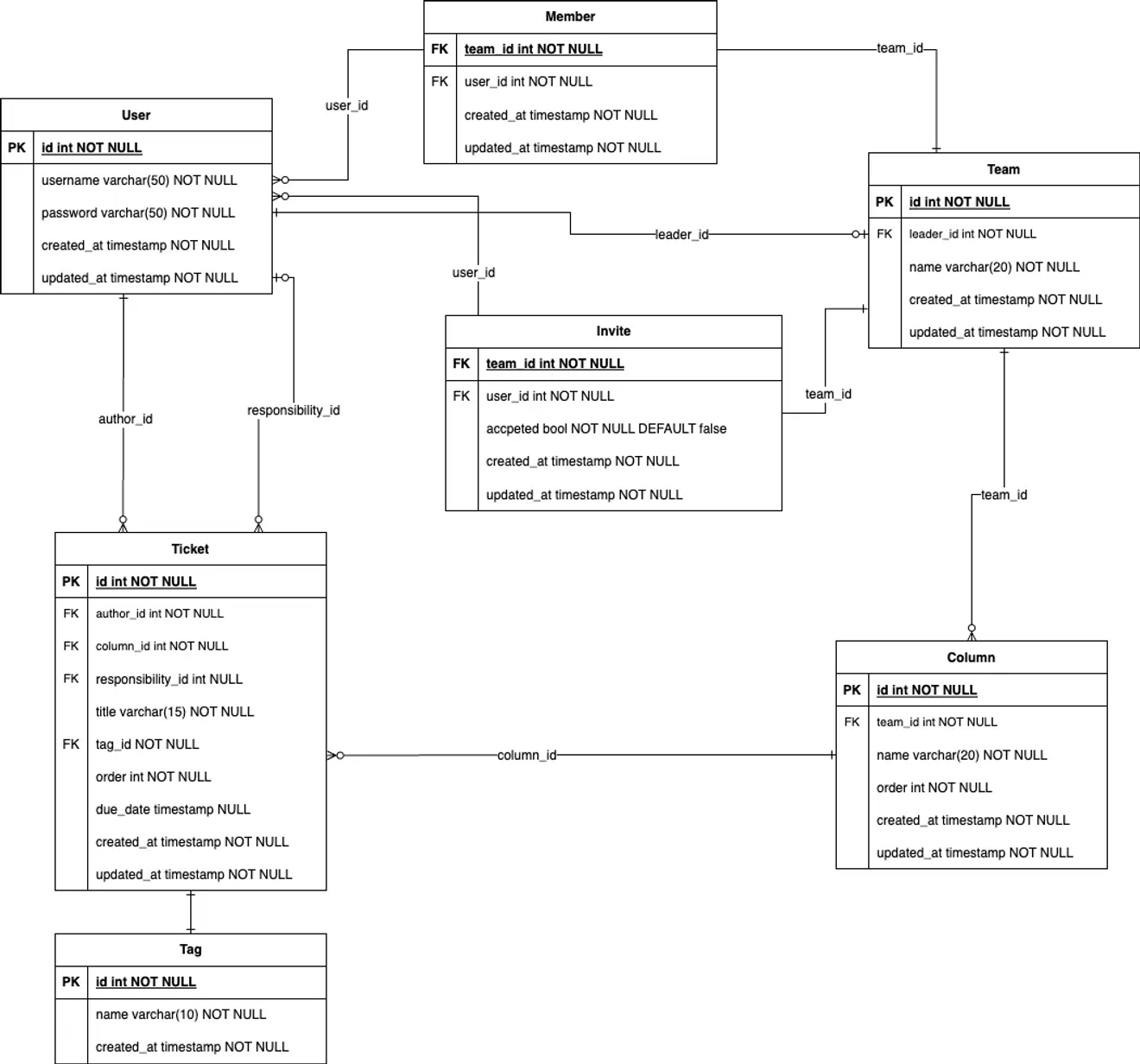
Vue d'ensemble de la normalisation
Maintenant, nous devons vérifier s'il satisfait à la 3ème forme normale, mais je trouve cela difficile car je ne comprends pas encore bien le concept.
Je me demande si je devrais séparer author_id et responsibility_id de la table Ticket dans une autre table, mais ce n'est pas une relation N:M et c'est une clé étrangère, donc j'ai décidé de passer à autre chose.
July 17, 2024
April 28, 2024
May 8, 2024
March 29, 2024
February 6, 2025
April 28, 2024
Commentaires0