Sujet
- #Modélisation relationnelle des données
- #Modélisation physique des données
- #Base de données
Création: 2024-04-09
Création: 2024-04-09 23:01
Si la modélisation de données logique consistait à créer des tables idéales adaptées aux bases de données relationnelles, la modélisation de données physique comprend la transformation de ces tables idéales en tables réellement utilisables, ainsi que la planification efficace de l'espace de stockage, la conception de la partition des objets, la conception d'index optimaux, etc., en mettant l'accent sur l'amélioration et l'optimisation des performances.
La méthode de recherche des requêtes lentes (Slow Query) qui provoquent des goulots d'étranglement lors de l'exploitation d'un service varie en fonction du type de SGBD etrequêtes lentesdoit être recherchée en utilisant ce mot-clé comme terme de recherche.
Cache
Si le problème de performances persiste malgré l'utilisation des méthodes ci-dessus, une opération appelée dénormalisation ou dénormalisation est effectuée.
Il s'agit de modifier la structure de la table.
La normalisation revient à sacrifier les performances de lecture pour faciliter les opérations d'écriture. Lorsque la normalisation est effectuée, il est nécessaire d'écrire des requêtes qui joignent les données des tables divisées en plusieurs parties.
Cependant, la normalisation n'entraîne pas nécessairement une baisse des performances, il est donc essentiel de bien comprendre le problème et de l'examiner avant de procéder à une dénormalisation.
Le lien ci-dessous est un bon article qui traite de ladénormalisationque nous aborderons plus tard.
Tout d'abord, il faut savoir que la dénormalisation doit être effectuée après la normalisation. Une table non normalisée n'est pas toujours idéale au départ.
Comme il ne s'agit pas d'une connaissance immédiatement nécessaire pour le moment, nous allons simplement la garder à l'esprit.
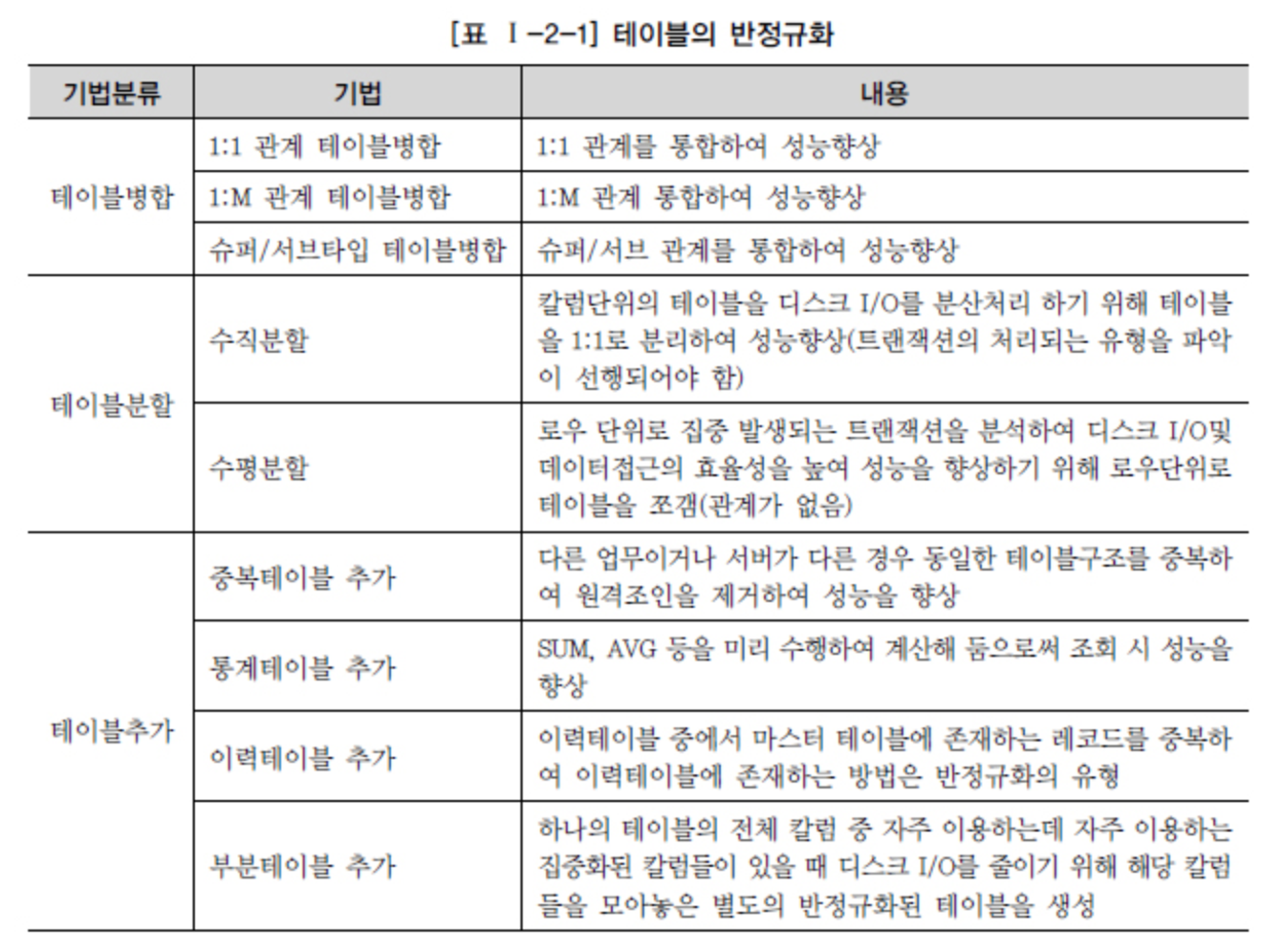
Source - DataOnAir - Dénormalisation et performance
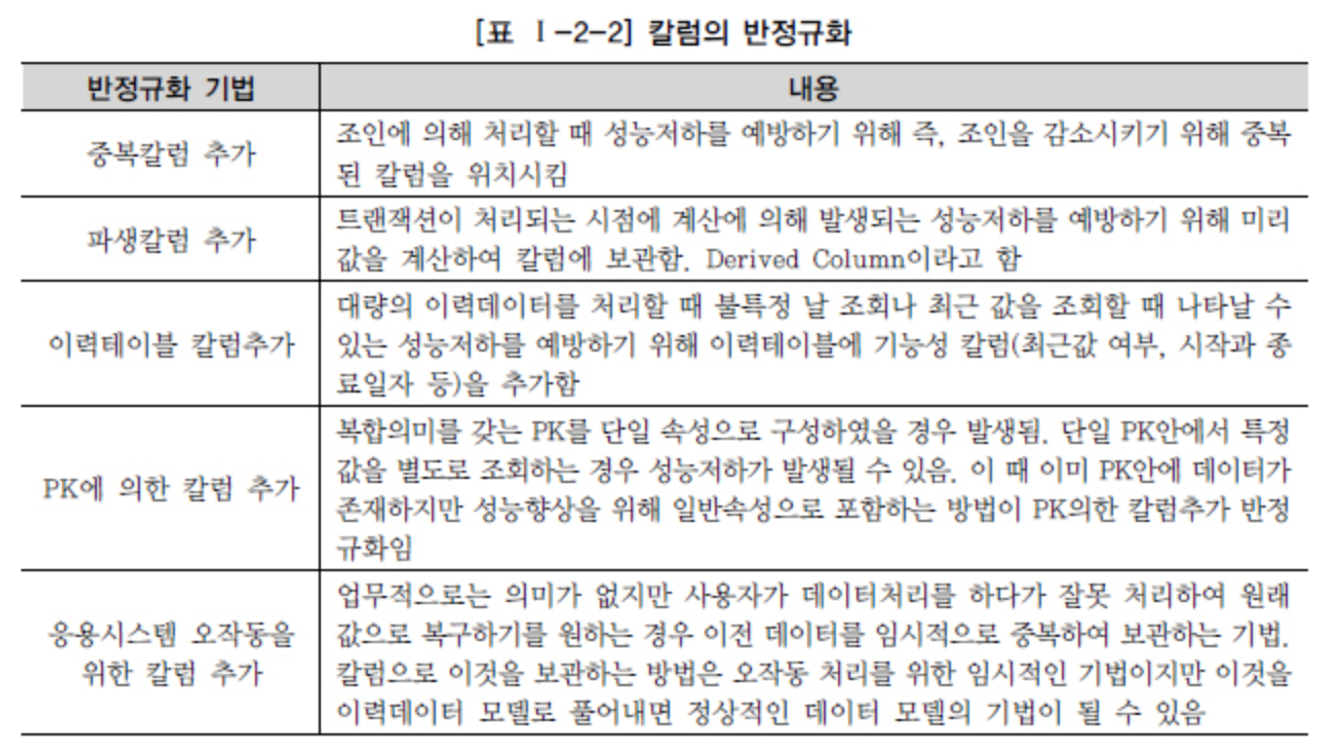
Source DataOnAir - Dénormalisation et performance

Source - DataOnAir - Dénormalisation et performance
April 25, 2024
April 28, 2024
April 25, 2024
April 3, 2024
February 6, 2025
May 29, 2024
Commentaires0