विषय
- #रिलेशनल डेटा मॉडलिंग
- #तार्किक डेटा मॉडलिंग
- #डेटाबेस
रचना: 2024-04-09
रचना: 2024-04-09 12:21
आवश्यकता विश्लेषण और वैचारिक डेटा मॉडलिंग की तुलना में, तार्किक डेटा मॉडलिंग एक अधिक यांत्रिक प्रक्रिया है।
यह प्रक्रिया मुख्य रूप से मैपिंग नियम (Mapping Rule) के आधार पर ERD (Entity-Relationship Diagram) को परिवर्तित करने पर केंद्रित होती है, जो कि वैचारिक डेटा मॉडलिंग का आउटपुट है, ताकि इसे रिलेशनल डेटाबेस पैराडाइम के अनुरूप बनाया जा सके।
सबसे पहले, विदेशी कुंजी (FK) रहित टेबल को प्राथमिकता देकर प्रदर्शित करना आसान होता है।
1:1 रिलेशन में, दो टेबल के बीच निर्भरता संबंध का निरीक्षण किया जाता है और विदेशी कुंजी (FK) सेट किया जाता है।
इसे पैरेंट और चाइल्ड टेबल के रूप में देखा जा सकता है।
1:N रिलेशन में, 1 को N द्वारा संदर्भित किया जाता है, इसलिए N में विदेशी कुंजी (FK) सेट किया जाता है।
रिलेशनल डेटाबेस में N:M रिलेशन को संभालने के लिए, एक मध्यवर्ती टेबल (जिसे मैपिंग टेबल या कनेक्शन टेबल भी कहा जाता है) बनाकर प्रदर्शित किया जाता है।
यहां महत्वपूर्ण बात यह है कि मैपिंग टेबल के संदर्भ में, दोनों टेबल की कार्डिनैलिटी और वैकल्पिकता (Optionalilty) को प्रदर्शित किया जाना चाहिए।
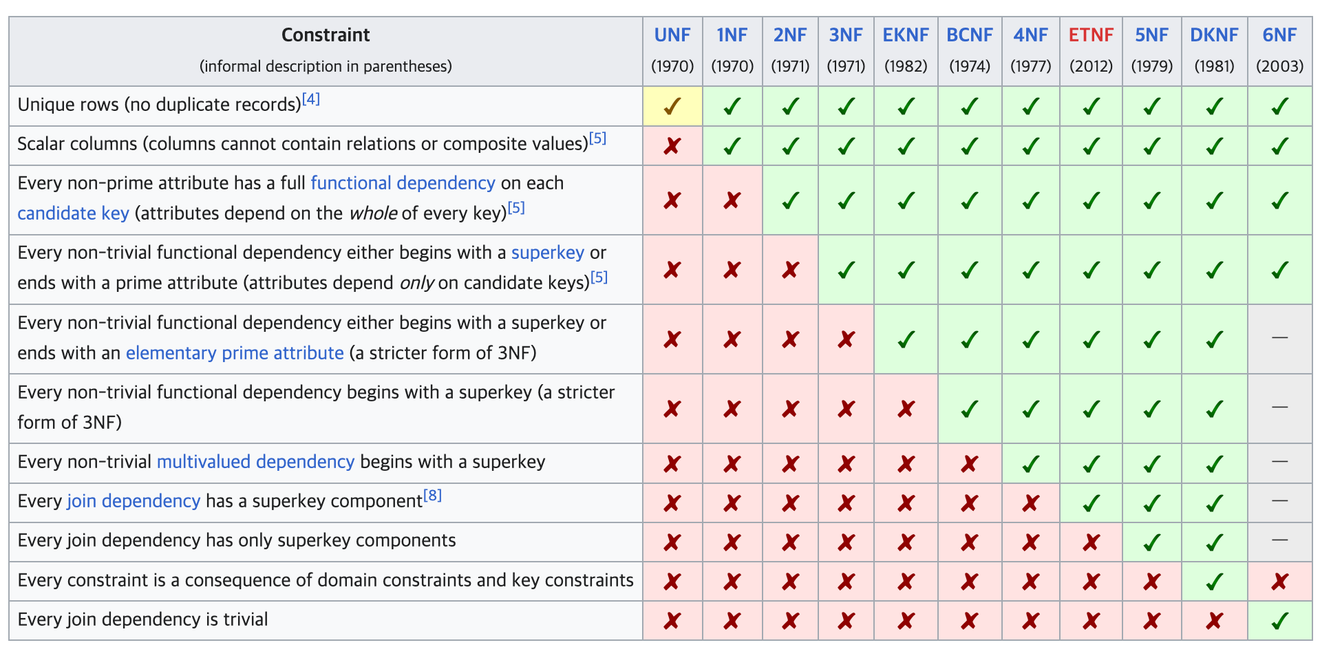
विकिपीडिया - डेटाबेस सामान्यीकरण
यह एक ऐसी प्रक्रिया है जिसमें अपरिष्कृत टेबल को रिलेशनल डेटाबेस के अनुकूल तालिका में बदल दिया जाता है।
उद्योग में उपयोग की जाने वाली सामान्यीकरण प्रक्रिया तीसरे सामान्य रूप (3NF) तक सीमित है, जबकि उसके बाद के सामान्यीकरण चरण मुख्य रूप से शैक्षणिक उद्देश्यों के लिए उपयोग किए जाते हैं।
सामान्यीकरण को एक समय में एक चरण करके क्रमिक रूप से किया जाना चाहिए।
प्रथम सामान्य रूप के मूल सिद्धांत को समझना थोड़ा मुश्किल हो सकता है, लेकिन यह मूल रूप से यह बताता है कि प्रत्येक कॉलम में केवल एक ही मान होना चाहिए।
यदि किसी कॉलम में कई मान हैं, अर्थात यह परमाणु नहीं है, तो SQL क्वेरी के साथ जॉइन करना मुश्किल हो सकता है और विभिन्न समस्याएं उत्पन्न हो सकती हैं।
यदि टेबल की किसी पंक्ति में डुप्लिकेट मान हैं, तो उस पंक्ति की निर्भरता वाले कॉलम को ढूंढकर अलग किया जाता है।
संक्रमणात्मक निर्भरता शब्द को समझना बहुत कठिन है। मेरी समझ से, यदि किसी विशिष्ट टेबल में किसी अन्य टेबल के पहचानकर्ता (अवश्य ही विदेशी कुंजी (FK) को छोड़कर) को दर्शाने वाले मान एक से अधिक हैं, तो उसे संक्रमणात्मक निर्भरता कहा जाता है।
April 28, 2024
April 3, 2024
April 28, 2024
April 26, 2024
April 28, 2024
January 13, 2025
टिप्पणियाँ0