Téma
- #Relációs adatmodellezés
- #Adatbázis
- #Logikai adatmodellezés
Létrehozva: 2024-04-09
Létrehozva: 2024-04-09 12:21
A követelmények elemzése és a konceptuális adatmodellezéshez képest a logikai adatmodellezés egy kissé mechanikusabb eljárás.
Főként a leképezési szabályok (Mapping Rule) alapján történik az ERD (Entity-Relationship Diagram) átalakítása, amely a konceptuális adatmodellezés eredménye, a relációs adatbázis paradigma követelményeinek megfelelően.
Először is, a FK-t nem tartalmazó táblák könnyebben ábrázolhatók.
Az 1:1 kapcsolatoknál megvizsgáljuk a két tábla közötti függőségi viszonyt, és beállítjuk az FK-t.
Szülő- és gyermek táblának tekinthetjük őket.
Az 1:N kapcsolatoknál az 1-et az N hivatkozza, ezért az N-hez állítjuk be az FK-t.
A relációs adatbázisokban az N:M kapcsolatok ábrázolásához egy köztes táblát (más néven leképezési vagy összekötő tábla) kell létrehozni.
Fontos megjegyezni, hogy a leképezési tábla alapján ki kell fejezni mindkét tábla kardinalitását és opcionális jellegét, amelyekre hivatkozik.
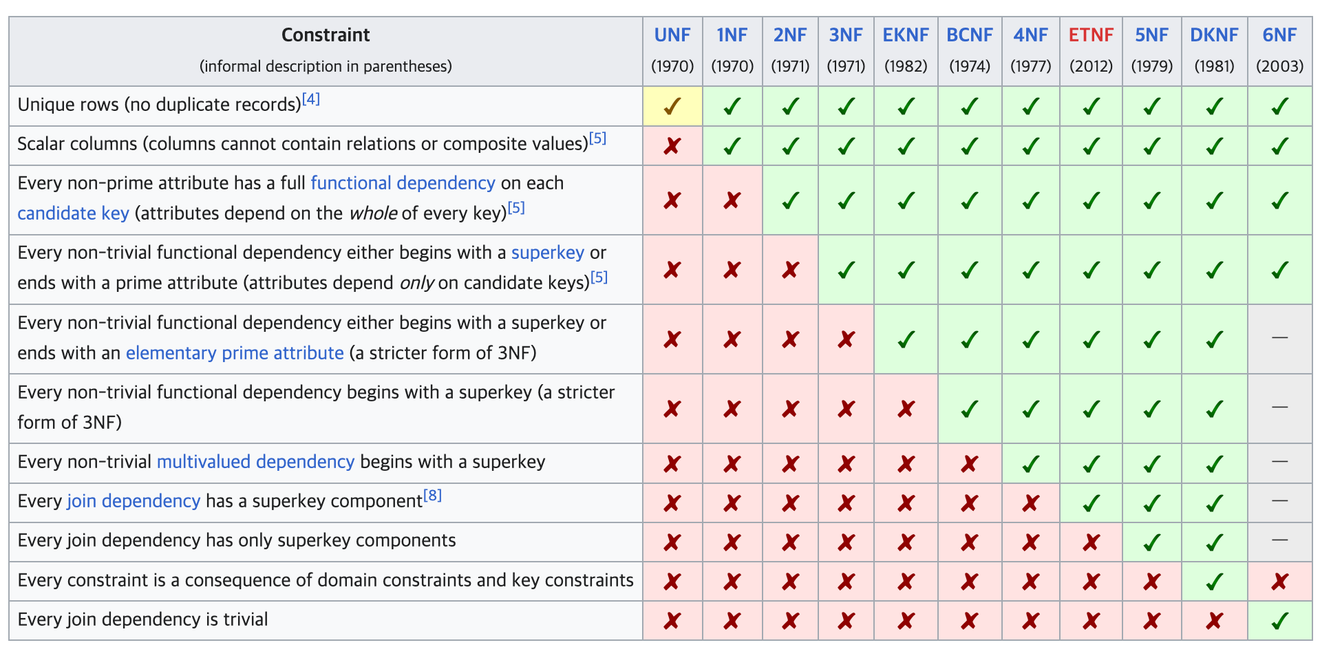
Wikipedia - Adatbázis-normalizálás
A nem finomított táblák relációs adatbázishoz illő táblákká alakításának folyamata.
Az iparban használt normalizálási folyamat a 3. normálformáig terjed, a továbbiak főként tudományos célokra szolgálnak.
A normalizálást lépésről lépésre, sorrendben kell végrehajtani.
Az 1. normálforma alapelveinek megértése elsőre nehéz lehet, de lényegében azt jelenti, hogy minden oszlopnak csak egyetlen értéket kell tartalmaznia.
Ha egy oszlopban több érték is szerepel, azaz nem atomikus, akkor nehezebb lesz SQL utasításokkal összekapcsolni, és különféle problémákat okozhat.
Ha a tábla soraiban ismétlődő értékek vannak, meg kell keresni azt az oszlopot, amelytől függnek, és szét kell választani.
A tranzitív függőség kifejezés nagyon nehéz lehet megérteni. Úgy tűnik, hogy ha egy adott táblában van egy vagy több olyan érték, amely implicit módon egy másik tábla azonosítóját jelenti (természetesen az FK-k kivételével), akkor azt tranzitív függőségnek nevezzük.
March 29, 2024
April 3, 2024
April 28, 2024
June 29, 2025
January 13, 2025
July 17, 2024
Hozzászólások0