Argomento
- #Database
- #Modellazione Logica dei Dati
- #Modellazione Relazionale dei Dati
Creato: 2024-04-09
Creato: 2024-04-09 12:21
Rispetto all'analisi dei requisiti e alla modellazione concettuale dei dati, la modellazione logica dei dati è una procedura più meccanica.
Il processo principale consiste nella conversione dell'ERD, che è il prodotto della modellazione concettuale dei dati, in un paradigma di database relazionale in base alle regole di mapping (Mapping Rule).
È più facile iniziare con la tabella senza FK.
Nella relazione 1:1, si esamina la relazione di dipendenza tra le due tabelle e si imposta l'FK.
Possono essere viste come tabella padre e tabella figlio.
Nella relazione 1:N, poiché 1 viene referenziato da N, l'FK viene impostato su N.
Per gestire la relazione N:M in un database relazionale, viene creata una tabella intermedia (chiamata anche tabella di mapping o tabella di collegamento) per rappresentarla.
A questo punto, è importante esprimere la cardinalità e l'optionalità di entrambe le tabelle referenziate in base alla tabella di mapping.
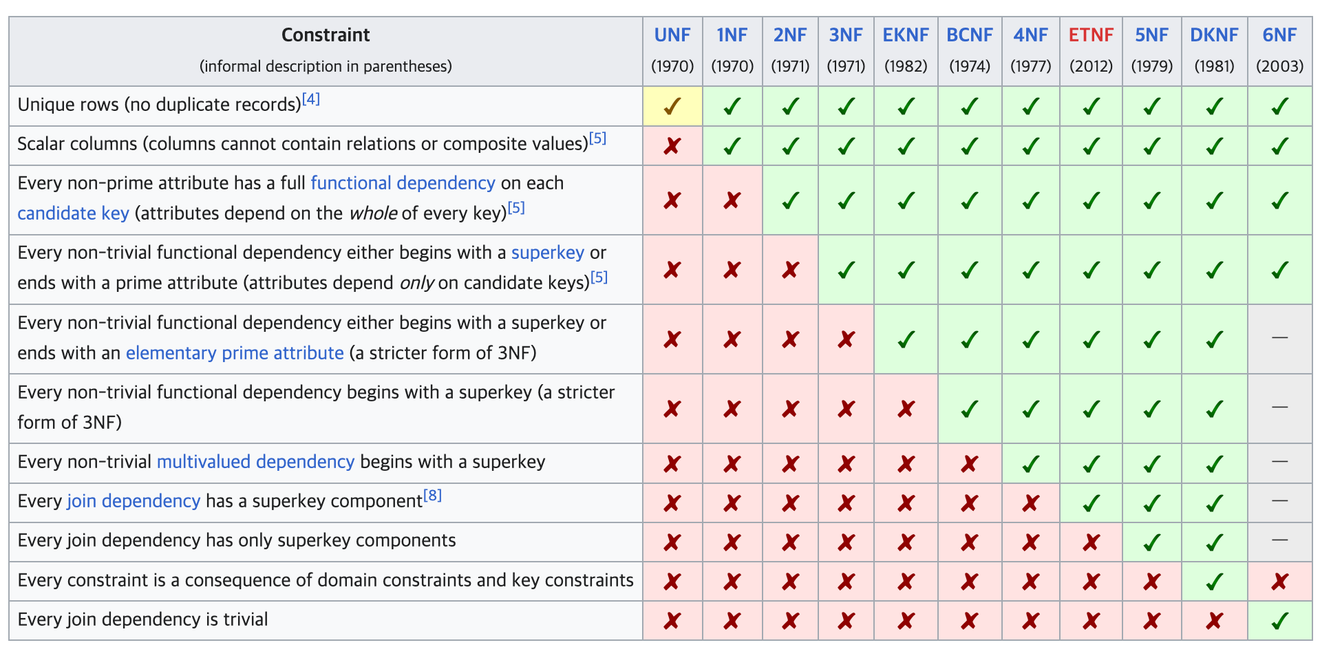
Wikipedia - Normalizzazione del Database
È il processo di trasformazione di una tabella non raffinata in una tabella adatta a un database relazionale.
Il processo di normalizzazione utilizzato a livello industriale arriva fino alla terza forma normale, mentre le forme successive vengono utilizzate principalmente nel campo accademico.
La normalizzazione deve essere eseguita sequenzialmente, un passaggio alla volta.
Se si guarda al principio fondamentale della prima forma normale, anche se è difficile da capire, significa semplicemente che ogni colonna deve contenere un solo valore.
Se una colonna contiene più valori, ovvero non è atomica, può essere difficile eseguire la join con le istruzioni SQL e possono verificarsi vari problemi.
Se ci sono valori duplicati nelle righe della tabella, si trova la colonna da cui dipende tale riga e la si separa.
La parola dipendenza transitiva è molto difficile da capire. Per quanto ho capito, se in una determinata tabella ci sono uno o più valori che implicano implicitamente l'identificatore di un'altra tabella (escluso l'FK), sembra che ciò venga definito dipendenza transitiva.
February 6, 2025
April 3, 2024
March 29, 2024
April 28, 2024
July 17, 2024
May 21, 2024
Commenti0