Argomento
- #Database
- #Modellazione fisica dei dati
- #Modellazione dati relazionale
Creato: 2024-04-09
Creato: 2024-04-09 23:01
Se la modellazione logica dei dati consisteva nel creare tabelle ideali adatte a un database relazionale, la modellazione fisica dei dati comprende l'attività di trasformare le tabelle ideali in tabelle utilizzabili nella pratica, considerando in modo prioritario il miglioramento delle prestazioni e l'ottimizzazione, tra cui la pianificazione efficiente dello spazio di archiviazione, la progettazione della partizione degli oggetti e la progettazione di indici ottimali.
Il modo in cui si trovano le query lente (slow query) che causano colli di bottiglia durante il funzionamento del servizio varia a seconda del tipo di DBMS equery lentedeve essere cercato utilizzando questa parola chiave.
Cache
Se il problema delle prestazioni non viene risolto con i metodi sopra descritti, viene eseguita un'operazione denominata denormalizzazione o reverse normalization.
Si tratta di modificare la struttura della tabella.
La normalizzazione è come sacrificare le prestazioni di lettura per la comodità delle operazioni di scrittura. Quando si esegue la normalizzazione, è necessario scrivere una query di join per i dati delle tabelle suddivise in più parti.
Tuttavia, la normalizzazione non riduce necessariamente le prestazioni, quindi è necessario identificare e esaminare correttamente il problema prima di procedere alla denormalizzazione.
Il link qui sotto è un buon articolo che tratta ladenormalizzazioneche verrà trattata in seguito.
La prima cosa da ricordare è che la denormalizzazione deve essere eseguita dopo aver eseguito la normalizzazione. Una tabella non normalizzata fin dall'inizio non è sempre una buona cosa.
Per ora, non è una conoscenza che ci serve immediatamente, quindi la prenderemo solo come nota.
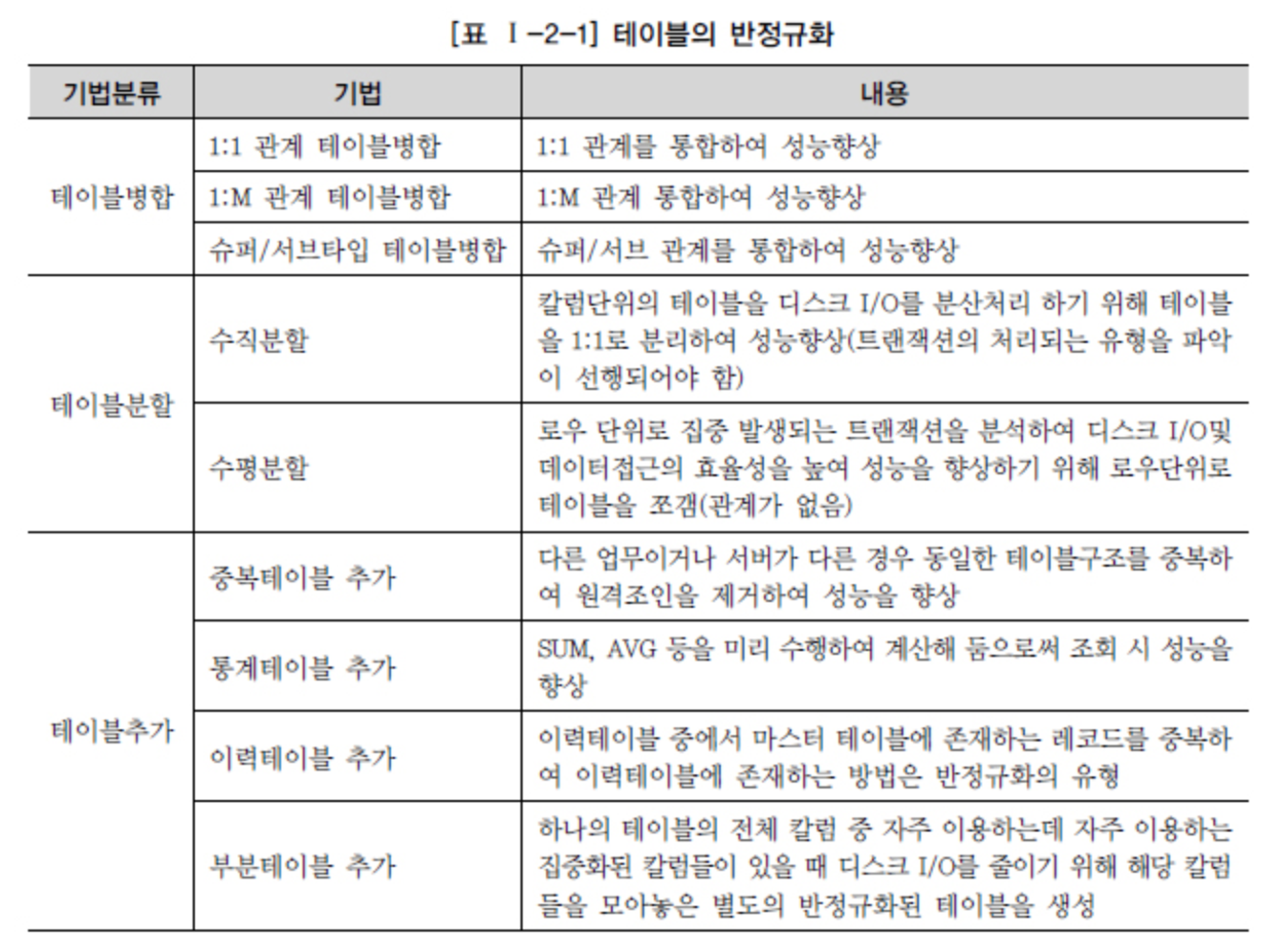
Fonte - DataOnAir - Denormalizzazione e prestazioni
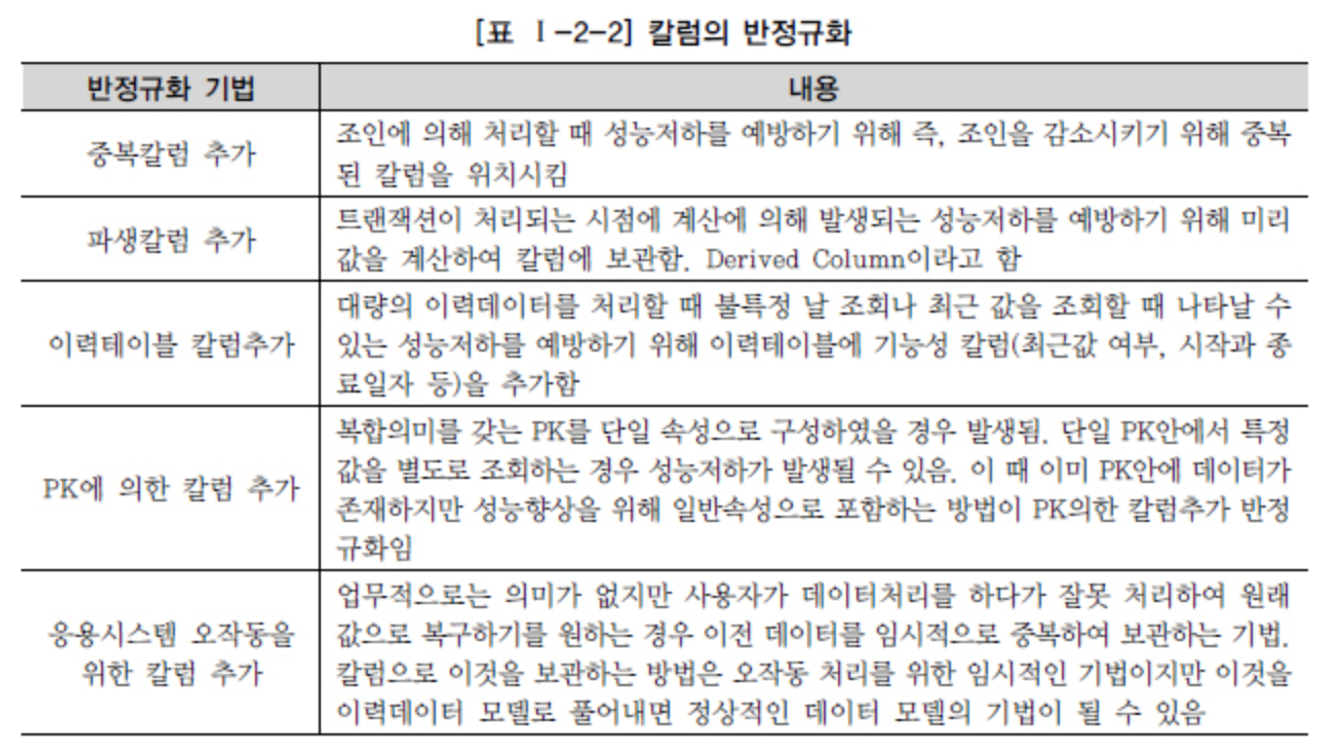
Fonte DataOnAir - Denormalizzazione e prestazioni

Fonte - DataOnAir - Denormalizzazione e prestazioni
April 25, 2024
April 3, 2024
November 29, 2024
April 25, 2024
April 28, 2024
February 6, 2025
Commenti0