Temat
- #Relacyjne modelowanie danych
- #Baza danych
- #Logiczne modelowanie danych
Utworzono: 2024-04-09
Utworzono: 2024-04-09 12:21
W porównaniu do analizy wymagań i koncepcyjnego modelowania danych, logiczne modelowanie danych jest bardziej mechanicznym procesem.
Głównym elementem jest proces konwersji diagramu ERD (Entity-Relationship Diagram), będącego wynikiem koncepcyjnego modelowania danych, do paradygmatu relacyjnej bazy danych, na podstawie reguł mapowania (Mapping Rule).
Najpierw najlepiej jest przedstawić tabele, które nie posiadają kluczy obcych (FK).
W relacji 1:1 należy zbadać zależność między dwiema tabelami i ustawić klucz obcy (FK).
Można je traktować jako tabelę nadrzędną i podrzędną.
W relacji 1:N, ponieważ 1 jest referencjonowane przez N, klucz obcy (FK) jest ustawiony w N.
W celu obsługi relacji N:M w relacyjnej bazie danych, tworzona jest tabela pośrednia (zwana również tabelą mapowania lub tabelą łącznikową) w celu jej reprezentacji.
W tym przypadku ważne jest, aby przedstawić kardynalność i opcjonalność obu tabel referencjonowanych na podstawie tabeli mapowania.
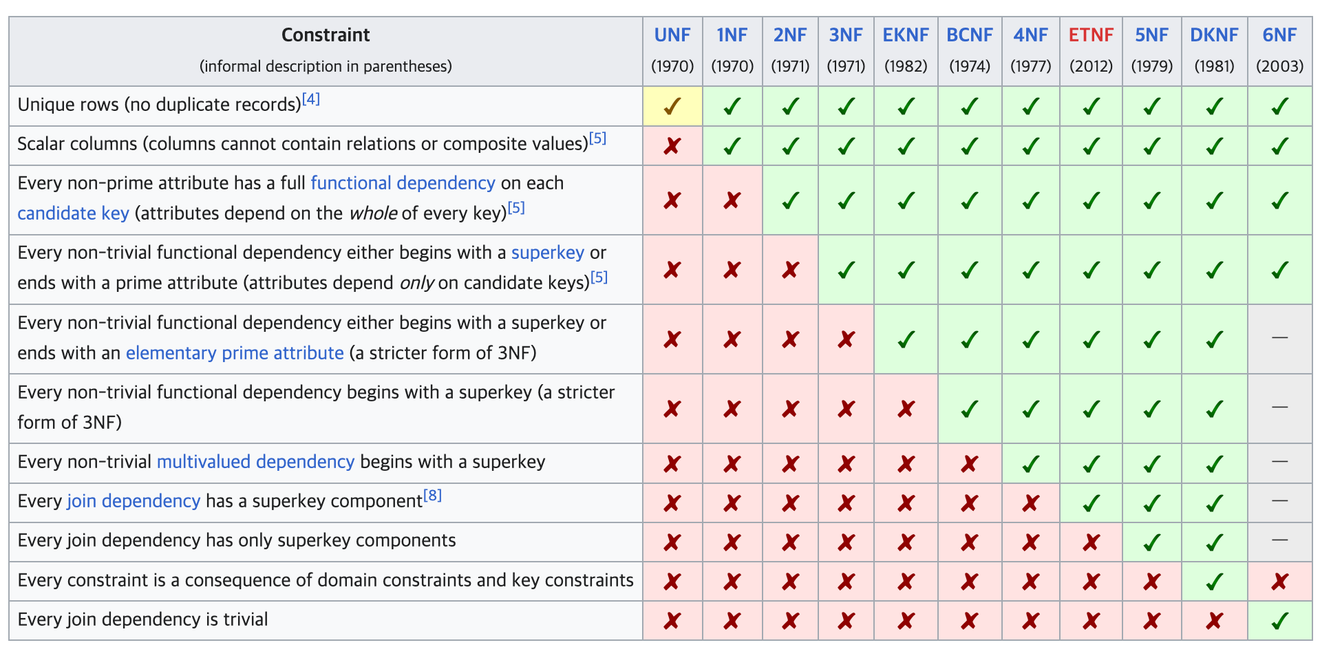
Wikipedia - Normalizacja bazy danych
Jest to proces przekształcania nieprzetworzonej tabeli w tabelę odpowiednią dla relacyjnej bazy danych.
W zastosowaniach przemysłowych stosuje się proces normalizacji do 3NF (Trzecia Forma Normalna), a dalsze etapy normalizacji są wykorzystywane głównie w środowisku akademickim.
Normalizacja powinna być przeprowadzana sekwencyjnie, krok po kroku.
Zasada pierwsza forma normalna może być trudna do zrozumienia, ale w zasadzie oznacza, że każda kolumna powinna zawierać tylko jedną wartość.
Jeśli w jednej kolumnie znajduje się wiele wartości, czyli nie jest ona atomowa, może to prowadzić do problemów, takich jak trudności z łączeniem (JOIN) za pomocą instrukcji SQL oraz innych problemów.
Jeśli w wierszach tabeli istnieją powtarzające się wartości, należy znaleźć kolumnę, od której zależy ten wiersz, i rozdzielić je.
Pojęcie zależności przechodniej jest bardzo trudne do zrozumienia. Z mojego zrozumienia, jeśli w danej tabeli istnieje co najmniej jedna wartość (oczywiście z wyjątkiem klucza obcego FK), która pośrednio odnosi się do identyfikatora innej tabeli, to można to nazwać zależnością przechodnią.
April 3, 2024
April 28, 2024
March 29, 2024
February 6, 2025
July 17, 2024
April 28, 2024
Komentarze0