Temat
- #Relacyjne modelowanie danych
- #Fizyczne modelowanie danych
- #Baza danych
Utworzono: 2024-04-09
Utworzono: 2024-04-09 23:01
Jeśli logiczne modelowanie danych polegało na tworzeniu idealnych tabel odpowiednich dla relacyjnych baz danych, to fizyczne modelowanie danych obejmuje tworzenie tych idealnych tabel w rzeczywiste tabele, a także planowanie efektywnego wykorzystania przestrzeni dyskowej, projektowanie partycjonowania obiektów i optymalne projektowanie indeksów, koncentrując się na poprawie wydajności i optymalizacji.
Metoda wyszukiwania powolnych zapytań (ang. slow query), które powodują wąskie gardła podczas działania usługi, różni się w zależności od typu DBMS, awolne zapytania (ang. slow query)należy wyszukiwać za pomocą odpowiednich słów kluczowych.
Pamięć podręczna (ang. Cache)
Jeśli powyższe metody nie rozwiążą problemu wydajności, należy przeprowadzić proces zwany denormalizacją lub odwróconą normalizacją.
Polega on na modyfikacji struktury tabel.
Normalizacja jest jak rezygnacja z wydajności odczytu na rzecz wygody operacji zapisu. Po znormalizowaniu danych, należy tworzyć zapytania z połączeniami (ang. join) dla danych z rozdzielonych tabel.
Jednak normalizacja nie zawsze obniża wydajność, dlatego przed przeprowadzeniem denormalizacji należy dokładnie zidentyfikować i zbadać problem.
Poniższy link prowadzi do wartościowego artykułu opisującego denormalizację, którą omówimy w dalszej części.
Należy pamiętać, że denormalizacja powinna być przeprowadzana po normalizacji. Początkowo tabele nie znormalizowane nie są najlepszym rozwiązaniem.
Na razie nie jest to wiedza niezbędna, więc wystarczy ją zapamiętać.
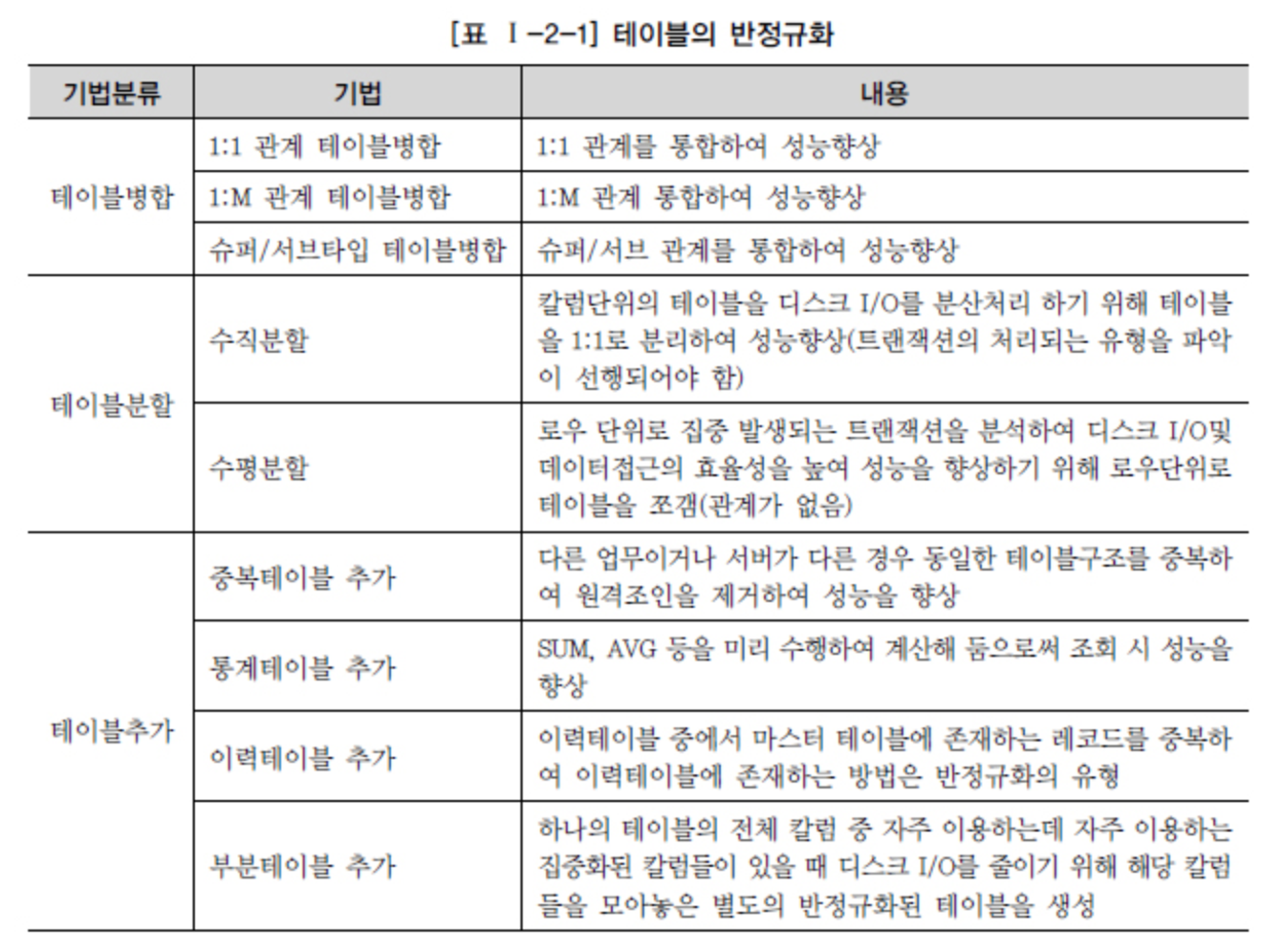
Źródło - DataOnAir - Denormalizacja i wydajność
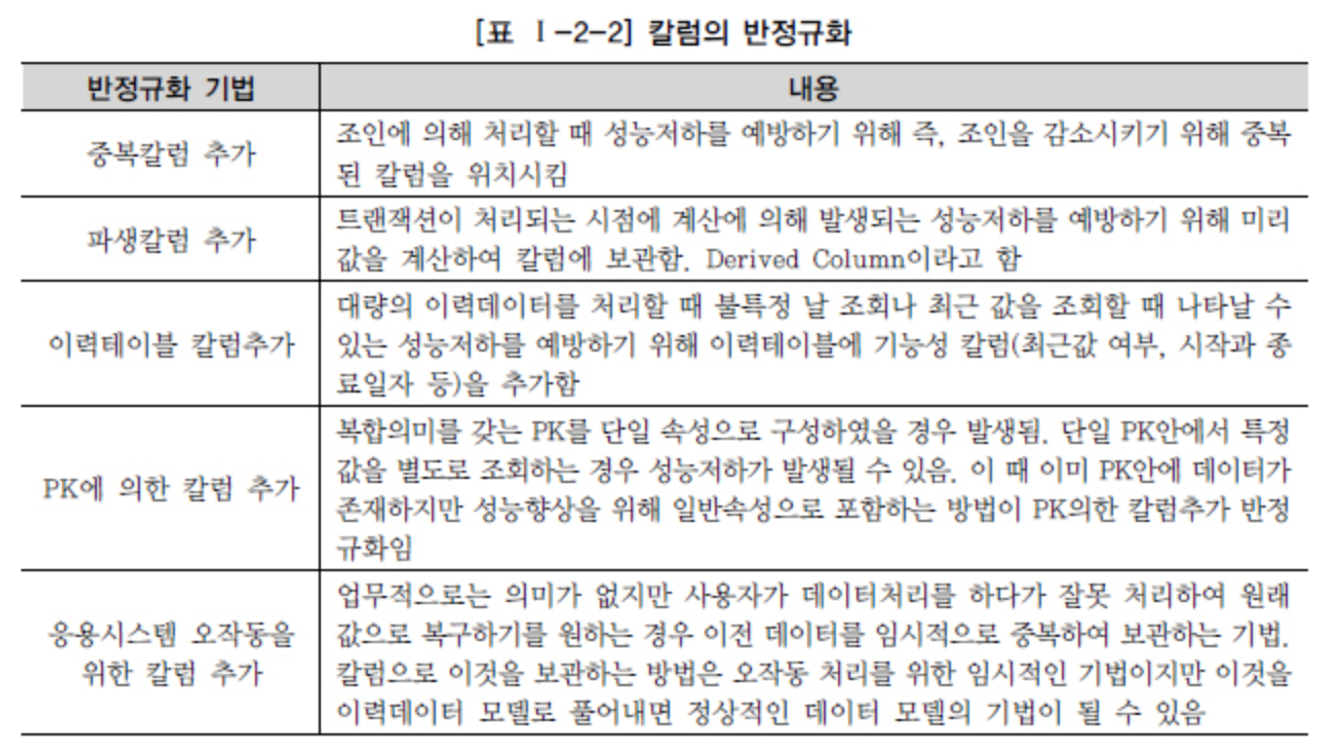
Źródło DataOnAir - Denormalizacja i wydajność

Źródło - DataOnAir - Denormalizacja i wydajność
April 25, 2024
April 28, 2024
April 3, 2024
April 25, 2024
February 6, 2025
November 29, 2024
Komentarze0