Assunto
- #Banco de Dados
- #Modelagem de Dados Relacional
- #Modelagem de Dados Lógica
Criado: 2024-04-09
Criado: 2024-04-09 12:21
Em comparação com a análise de requisitos e a modelagem de dados conceitual, a modelagem de dados lógica é um processo mais mecânico.
O processo é dominado pela conversão do ERD, que é o produto da modelagem de dados conceitual, para o paradigma de banco de dados relacional com base na Regra de Mapeamento (Mapping Rule).
É mais fácil expressar primeiro a tabela sem FK.
No relacionamento 1:1, o relacionamento de dependência entre as duas tabelas é verificado e a FK é definida.
Pode ser visto como uma tabela pai e uma tabela filho.
No relacionamento 1:N, uma vez que 1 é referenciado por N, a FK é definida em N.
Para lidar com o relacionamento N:M em um banco de dados relacional, uma tabela intermediária (também chamada de tabela de mapeamento ou tabela de junção) é criada e expressa.
Nesse caso, é importante expressar a cardinalidade e opcionalidade das duas tabelas referenciadas com base na tabela de mapeamento.
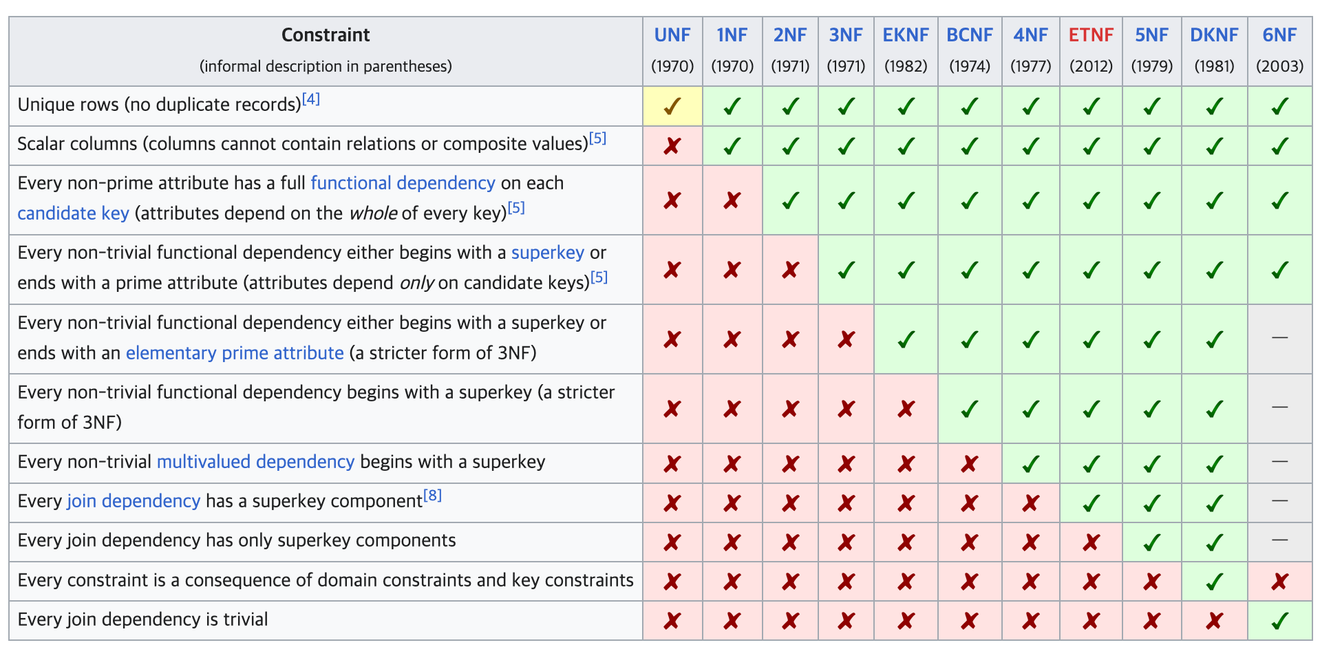
Wikipedia - Normalização de Banco de Dados
É o processo de transformar uma tabela não refinada em uma tabela adequada para um banco de dados relacional.
O processo de normalização usado na indústria vai até a 3ª forma normal, e as etapas subsequentes de normalização são usadas principalmente em pesquisas acadêmicas.
A normalização deve ser realizada sequencialmente, uma etapa de cada vez.
Ao olhar para o princípio fundamental da 1ª forma normal, é difícil entender o que isso significa, mas simplesmente significa que cada coluna deve conter apenas um valor.
Se vários valores estiverem em uma coluna, ou seja, se não for atômico, será difícil fazer junções com instruções SQL e vários problemas podem ocorrer.
Se houver valores duplicados em uma linha da tabela, encontre a coluna da qual essa linha depende e a separe.
A frase "dependência transitiva" é muito difícil de entender. Pelo que entendi, se houver um ou mais valores em uma determinada tabela que impliquem implicitamente o identificador de outra tabela (excluindo FK, é claro), isso parece ser chamado de dependência transitiva.
March 29, 2024
April 3, 2024
February 6, 2025
July 17, 2024
April 28, 2024
April 28, 2024
Comentários0