Тема
- #Реляционное моделирование данных
- #Нормализация
- #Логическое моделирование данных
Создано: 2024-04-09
Создано: 2024-04-09 15:32
Изучение и практика логического моделирования данных
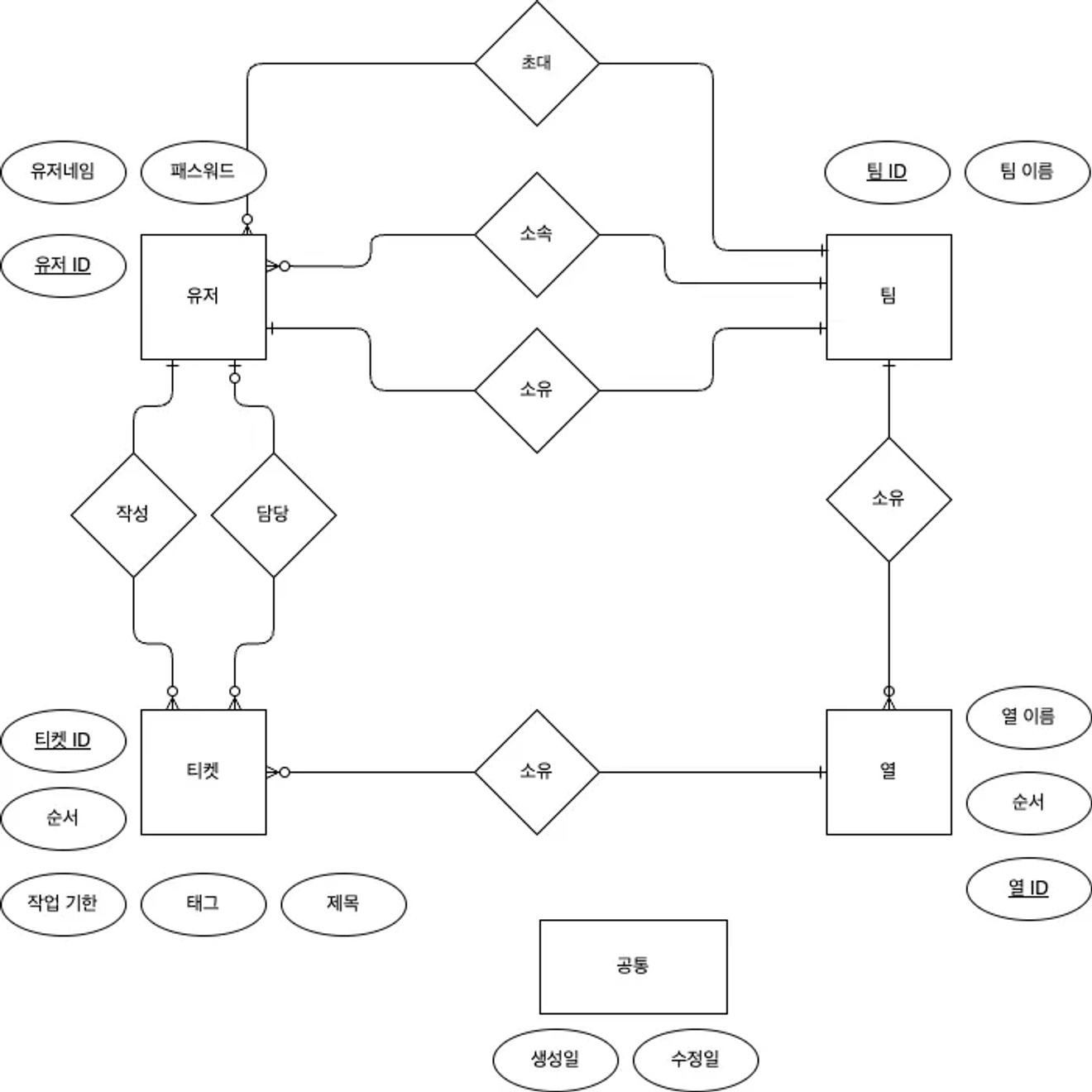
ERD концептуального моделирования данных
Сначала мы проходим процесс концептуального моделирования данных, а затем, используя эту ERD, выполняем логическое моделирование данных.
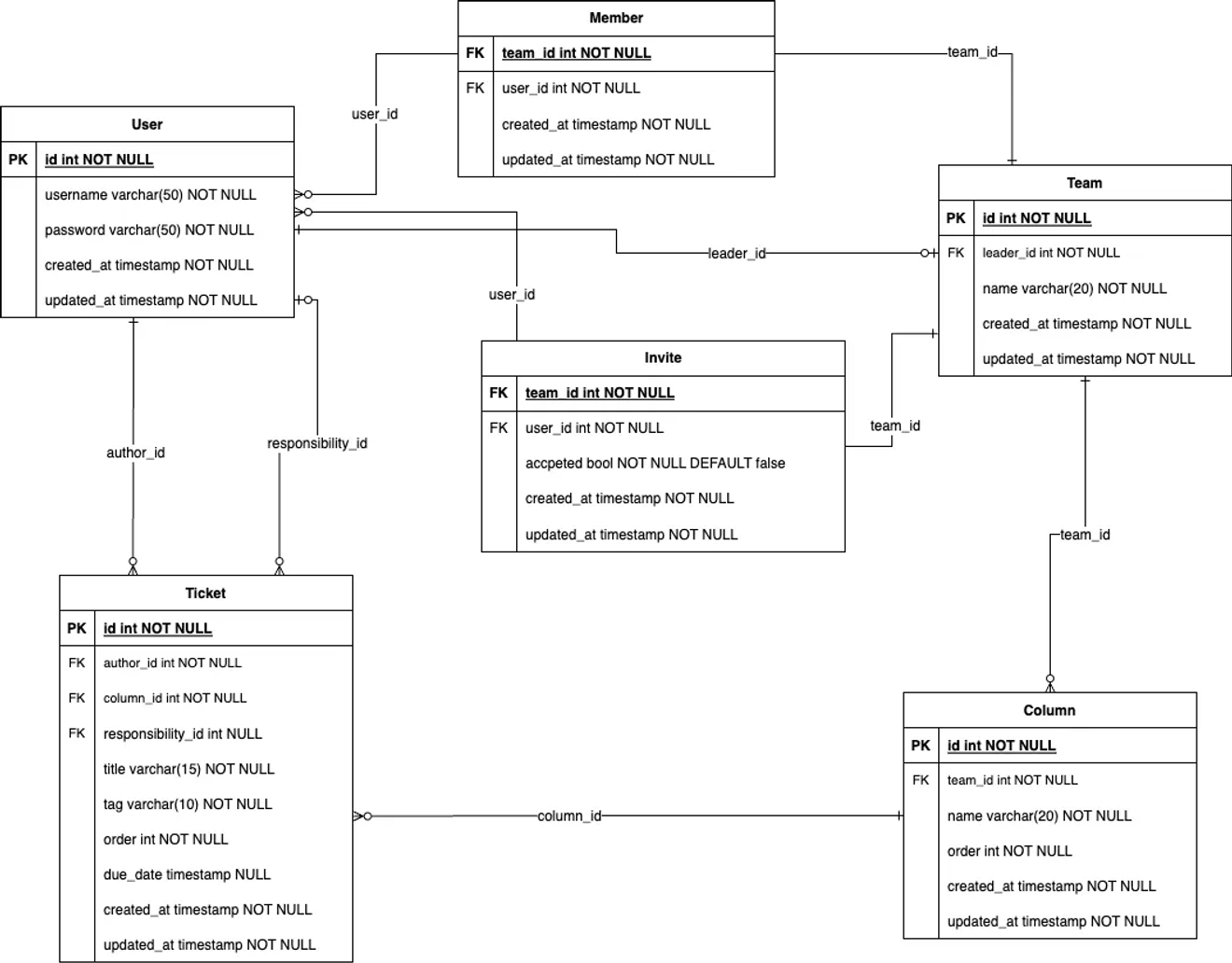
ERD логического моделирования данных
Некоторую сложность представляло необходимость учитывать связь с обеими таблицами, исходя из таблицы сопоставления.
После преобразования ERD концептуального моделирования данных в табличную форму выполняется нормализация.
Этапы нормализации должны выполняться последовательно. При рассмотрении вышеприведенной ERD можно заметить, что первая нормальная форма выполнена.
Для удовлетворения второй нормальной формы создается таблица Tag из поля Tag таблицы Ticket, а первичный ключ этого тега используется как внешний ключ.
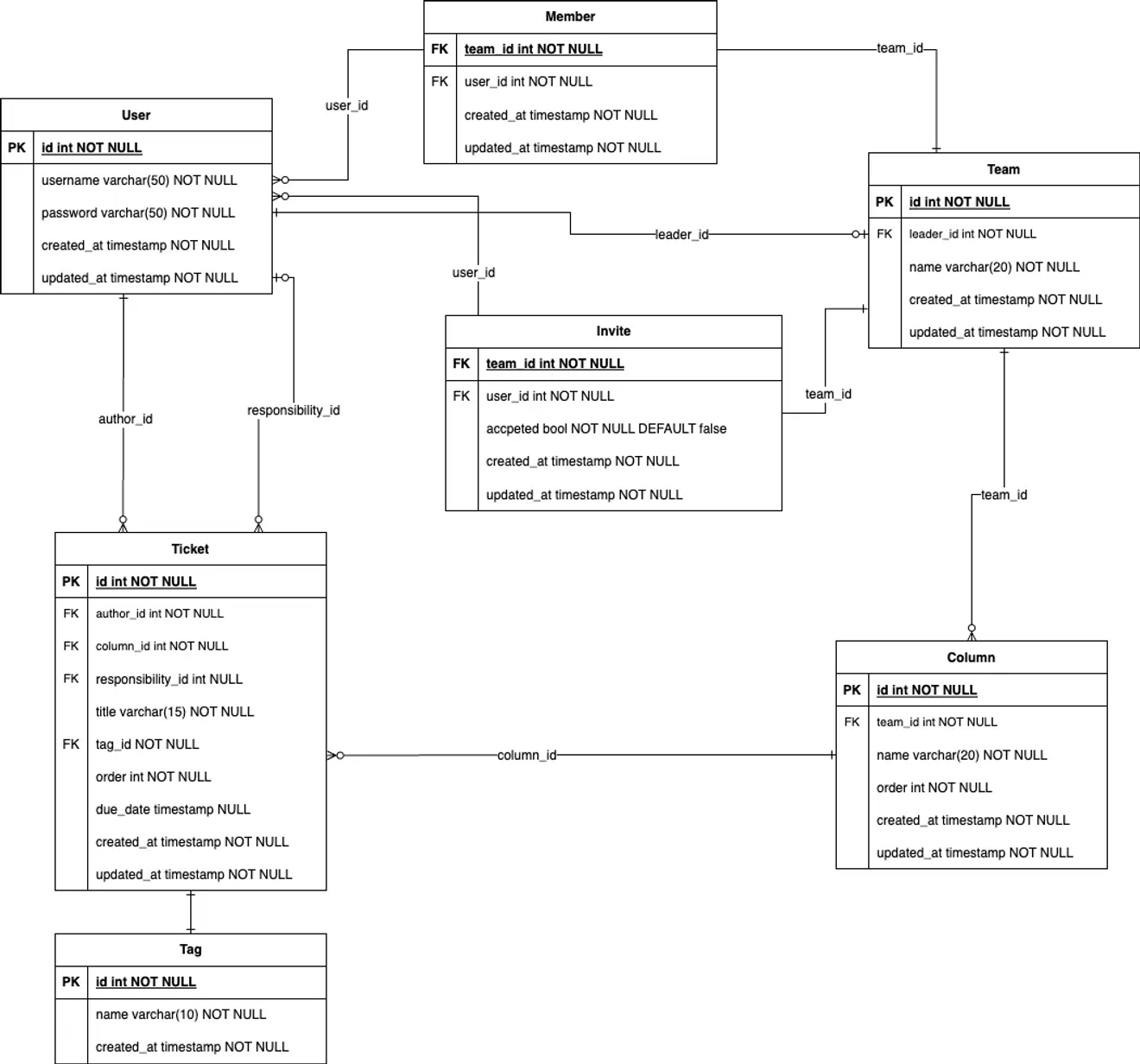
Результат нормализации
Теперь необходимо проверить, удовлетворяет ли таблица третьей нормальной форме, но из-за недостаточного понимания концепции это кажется сложным.
Возникает вопрос, следует ли разделять author_id и responsibility_id таблицы Ticket на другие таблицы. Это не отношение N:M, и это внешний ключ, поэтому было решено пропустить этот шаг.
April 28, 2024
July 17, 2024
May 8, 2024
February 6, 2025
April 3, 2024
April 28, 2024
Комментарии0