หัวข้อ
- #ฐานข้อมูล
- #การสร้างแบบจำลองข้อมูลเชิงสัมพันธ์
- #การสร้างแบบจำลองข้อมูลเชิงกายภาพ
สร้าง: 2024-04-09
สร้าง: 2024-04-09 23:01
หากการสร้างแบบจำลองข้อมูลเชิงตรรกะ (Logical Data Modeling) เป็นการสร้างตารางในอุดมคติที่เหมาะสมกับฐานข้อมูลแบบสัมพันธ์ การสร้างแบบจำลองข้อมูลเชิงกายภาพ (Physical Data Modeling) จะรวมถึงการสร้างตารางในอุดมคติให้เป็นตารางที่ใช้งานจริง พร้อมทั้งพิจารณาถึงการวางแผนการใช้พื้นที่จัดเก็บข้อมูลอย่างมีประสิทธิภาพ การออกแบบการแบ่งพาร์ติชันของออบเจ็กต์ และการออกแบบดัชนีที่ดีที่สุด เพื่อเน้นการปรับปรุงประสิทธิภาพและการเพิ่มประสิทธิภาพ
วิธีการค้นหาแบบสอบถามที่ช้า (Slow Query) ซึ่งเป็นสาเหตุของปัญหาคอขวดในระหว่างการดำเนินงานของบริการจะแตกต่างกันไปตามประเภทของ DBMS และแบบสอบถามที่ช้า (Slow Query)จำเป็นต้องค้นหาโดยใช้เป็นคำหลักในการค้นหา
แคช (Cache)
หากวิธีการข้างต้นไม่สามารถแก้ไขปัญหาประสิทธิภาพได้ จะดำเนินการที่เรียกว่าการทำให้เป็นปกติย้อนกลับ (Denormalization) หรือการทำให้ไม่เป็นปกติ (Denormalization)
นั่นคือการแก้ไขโครงสร้างของตาราง
การทำให้เป็นปกติ (Normalization) เหมือนกับการยอมแลกประสิทธิภาพในการอ่านเพื่อความสะดวกในการเขียน เนื่องจากเมื่อทำการทำให้เป็นปกติ (Normalization) แล้วจำเป็นต้องเขียนแบบสอบถามเพื่อเชื่อมต่อข้อมูลในตารางที่ถูกแบ่งออกเป็นหลายส่วน
อย่างไรก็ตาม การทำให้เป็นปกติ (Normalization) ไม่ได้ทำให้ประสิทธิภาพลดลงเสมอไป ดังนั้นก่อนที่จะดำเนินการทำให้เป็นปกติย้อนกลับ (Denormalization) จำเป็นต้องวิเคราะห์และตรวจสอบปัญหาอย่างถูกต้อง
ลิงก์ด้านล่างเป็นบทความที่ดีที่กล่าวถึงการทำให้เป็นปกติย้อนกลับ (Denormalization)ซึ่งเราจะกล่าวถึงต่อไป
สิ่งแรกที่ควรทราบคือ การทำให้เป็นปกติย้อนกลับ (Denormalization) ควรดำเนินการหลังจากทำการทำให้เป็นปกติ (Normalization) แล้ว การมีตารางที่ไม่เป็นปกติตั้งแต่แรกนั้นไม่ใช่เรื่องที่ดี
เนื่องจากในตอนนี้ยังไม่จำเป็นต้องใช้ความรู้ดังกล่าว จึงขอให้ทราบไว้เพียงเท่านั้น
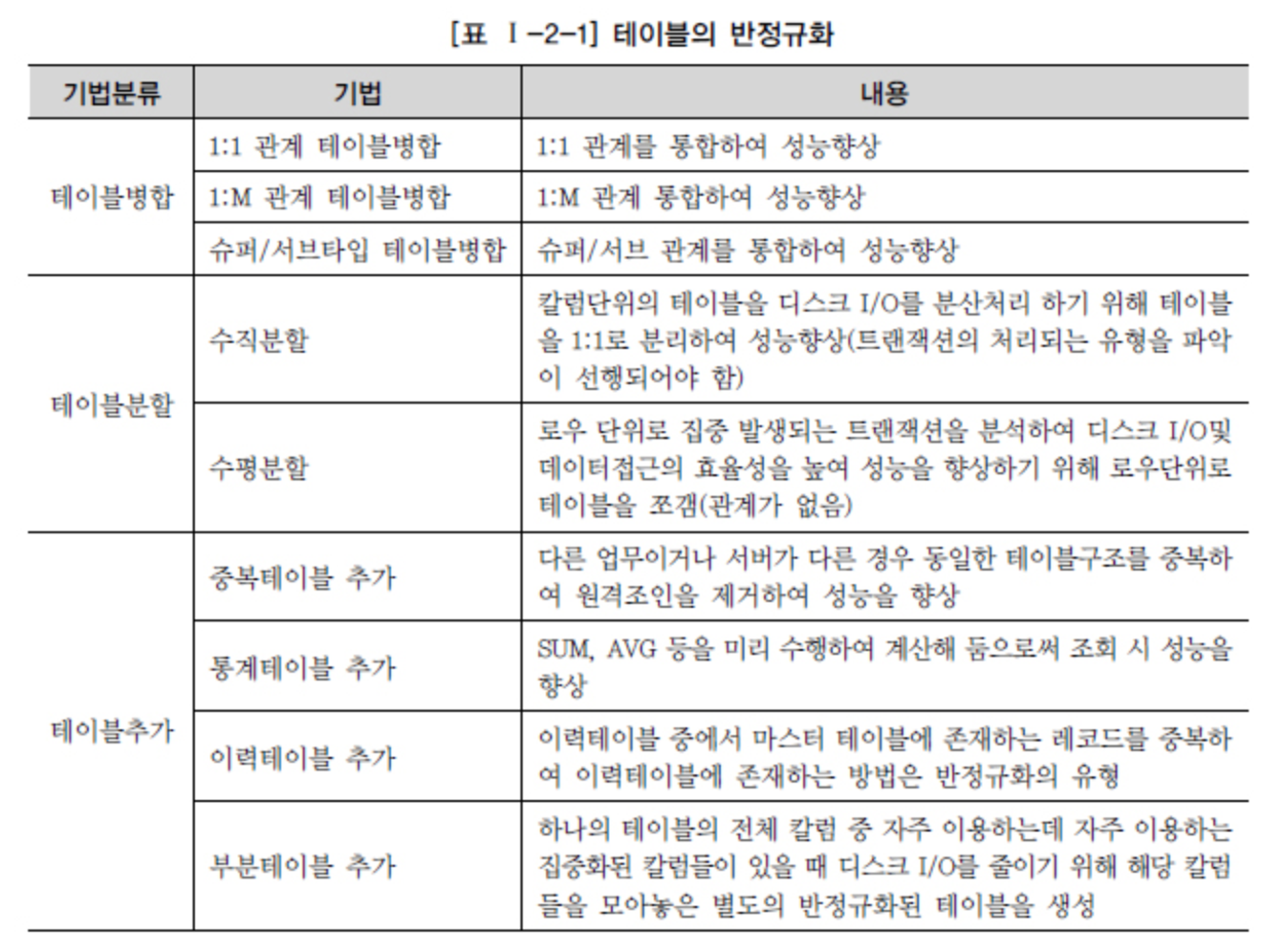
ที่มา - DataOnAir - การทำให้ไม่เป็นปกติและประสิทธิภาพ
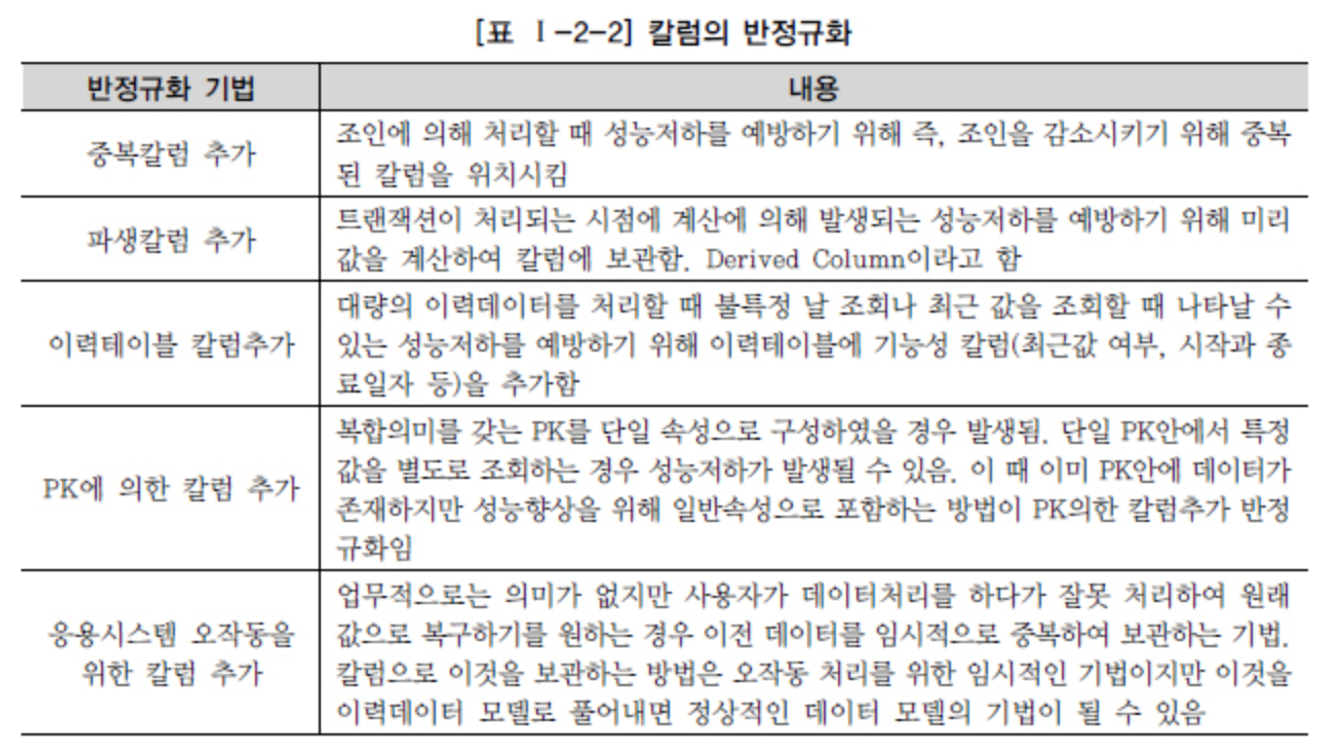
ที่มา DataOnAir - การทำให้ไม่เป็นปกติและประสิทธิภาพ

ที่มา - DataOnAir - การทำให้ไม่เป็นปกติและประสิทธิภาพ
April 25, 2024
April 3, 2024
April 25, 2024
April 28, 2024
February 6, 2025
November 29, 2024
ความคิดเห็น0