主题
- #資料庫
- #關聯式資料模型
- #邏輯資料模型
撰写: 2024-04-09
撰写: 2024-04-09 12:21
相較於需求分析和概念性資料模型化,邏輯性資料模型化是一個更為機械化的過程。
其主要過程是根據映射規則(Mapping Rule),將概念性資料模型化產出物ERD轉換為符合關聯式資料庫範式的過程。
首先,沒有FK的表格優先表達較為方便。
在1:1關係中,檢查兩個表格之間的依賴關係並設定FK。
可以視為父表格和子表格。
在1:N關係中,因為1被N參照,所以在N中設定FK。
在關聯式資料庫中,處理N:M關係需要建立中間表格(也稱為映射表格或連結表格)來表達。
此時,重點是要根據映射表格表達被參照的兩個表格的基數和選用性。
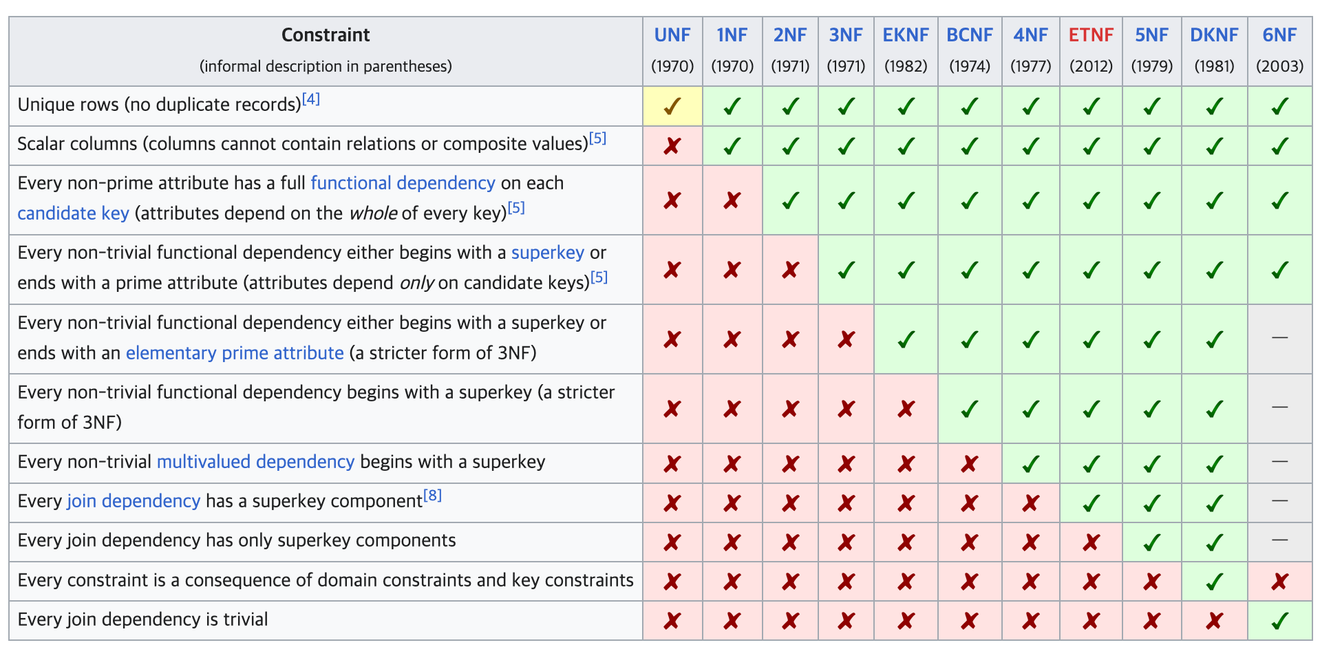
維基百科 - 資料庫正規化
將未經處理的表格轉換為適合關聯式資料庫的表格的過程。
產業上使用的正規化過程到第三正規化為止,之後的正規化過程主要用於學術研究。
正規化必須依序一步一步地進行。
雖然第一正規化的基本原則乍看之下難以理解,但簡單來說,就是每個欄位只能包含一個值。
如果一個欄位中包含多個值,也就是說不是原子性的,那麼不僅難以使用SQL語法進行聯結,還會造成各種問題。
如果表格的行中存在重複的值,則找到該行依賴的欄位並進行分離。
遞移函數依賴這個詞非常難以理解。依我的理解,如果特定表格中隱含地表示其他表格識別符號的值(當然不包括FK)超過一個,那麼似乎可以稱之為遞移函數依賴。
2024年3月29日
2024年4月3日
2024年4月28日
2024年4月28日
2024年4月28日
2025年2月6日
评论0