주제
- #물리적 데이터 모델링
- #데이터베이스
- #관계형 데이터 모델링
작성: 2024-04-09
작성: 2024-04-09 23:01
논리적 데이터 모델링이 관계형 데이터베이스에 맞는 이상적인 테이블을 만드는 작업이었다면, 물리적 데이터 모델링에서는 이상적인 테이블을 실제 사용할 테이블로 만드는 작업을 포함하여 저장공간의 효율적 사용 계획, 오브젝트 파티셔닝 설계, 최적의 인덱스 설계등 성능 향상과 최적화를 중점적으로 고려한다.
서비스 운영시 병목 현상을 일으키는 슬로우 쿼리를 찾는 방법은 DBMS의 종류마다 다르며 슬로우 쿼리를 키워드로 검색하여 찾아야한다.
캐시(Cache)
위의 방법으로도 성능 문제가 해결이 되지 않으면, 역정규화 또는 반정규화라고 불리는 작업을 진행한다.
테이블의 구조를 수술해서 고치는 것이다.
정규화는 쓰기 작업의 편리함을 위해서 읽기의 성능을 포기하는 것과 같다. 정규화를 하게 되면 여러개로 쪼개진 테이블의 데이터들을 조인하는 쿼리를 작성 해야한다.
하지만 정규화가 반드시 성능을 떨어트리진 않으므로 역정규화를 진행하기 전에 꼭 문제를 올바르게 파악하고 검토 해야한다.
아래의 링크는 앞으로 다룰 역정규화에 대해서 다루고 있는 좋은 글이다.
먼저 알아두어야 할 것은, 정규화를 진행하고 난 뒤에 역정규화를 진행 해야 한다는 점이다. 처음부터 비정규화 테이블이 좋은 것은 아니다.
일단 지금 당장 필요한 지식은 아니기 때문에, 알아두고만 넘어가려고 한다.
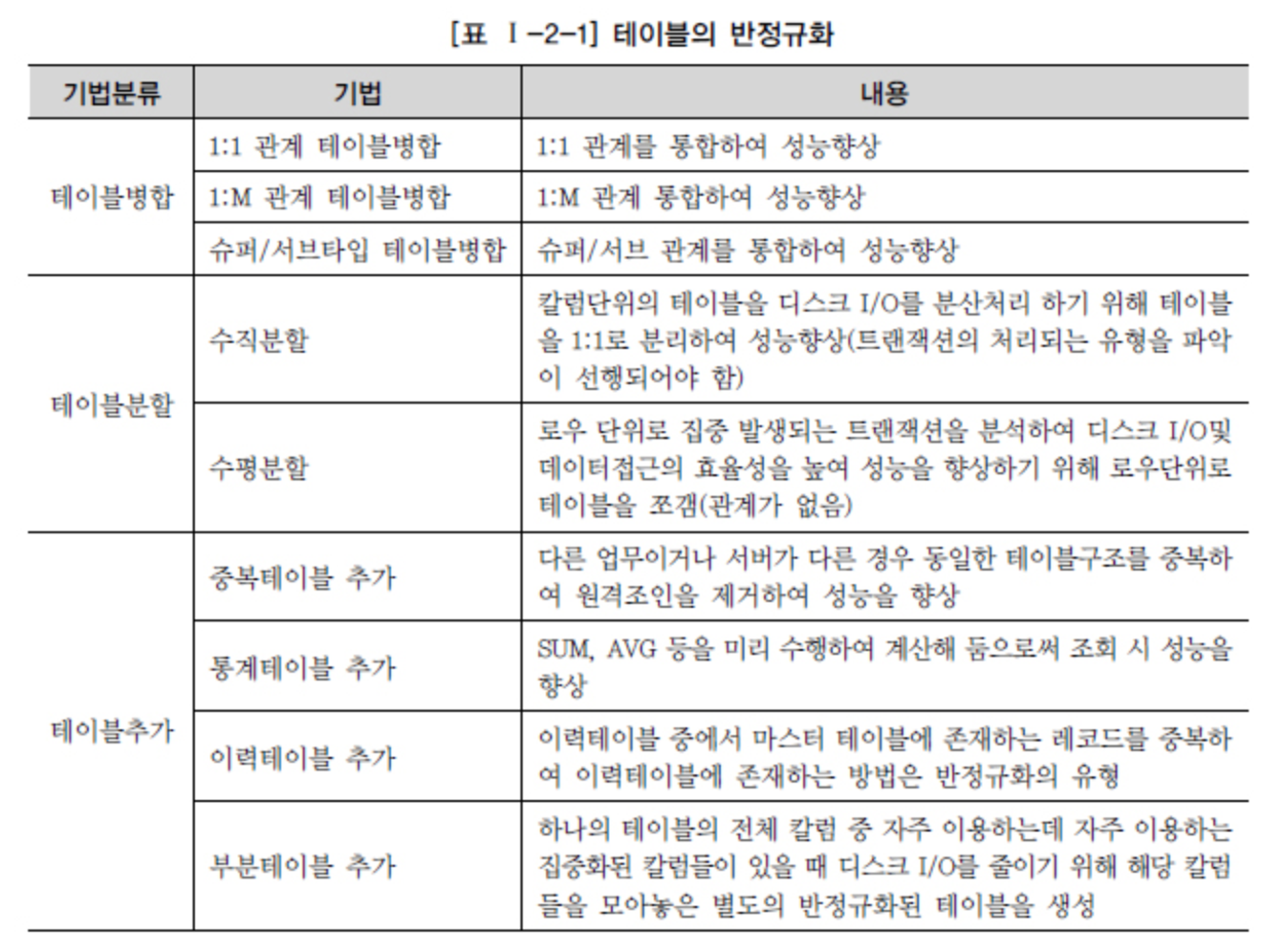
출처 - DataOnAir - 반정규화와 성능
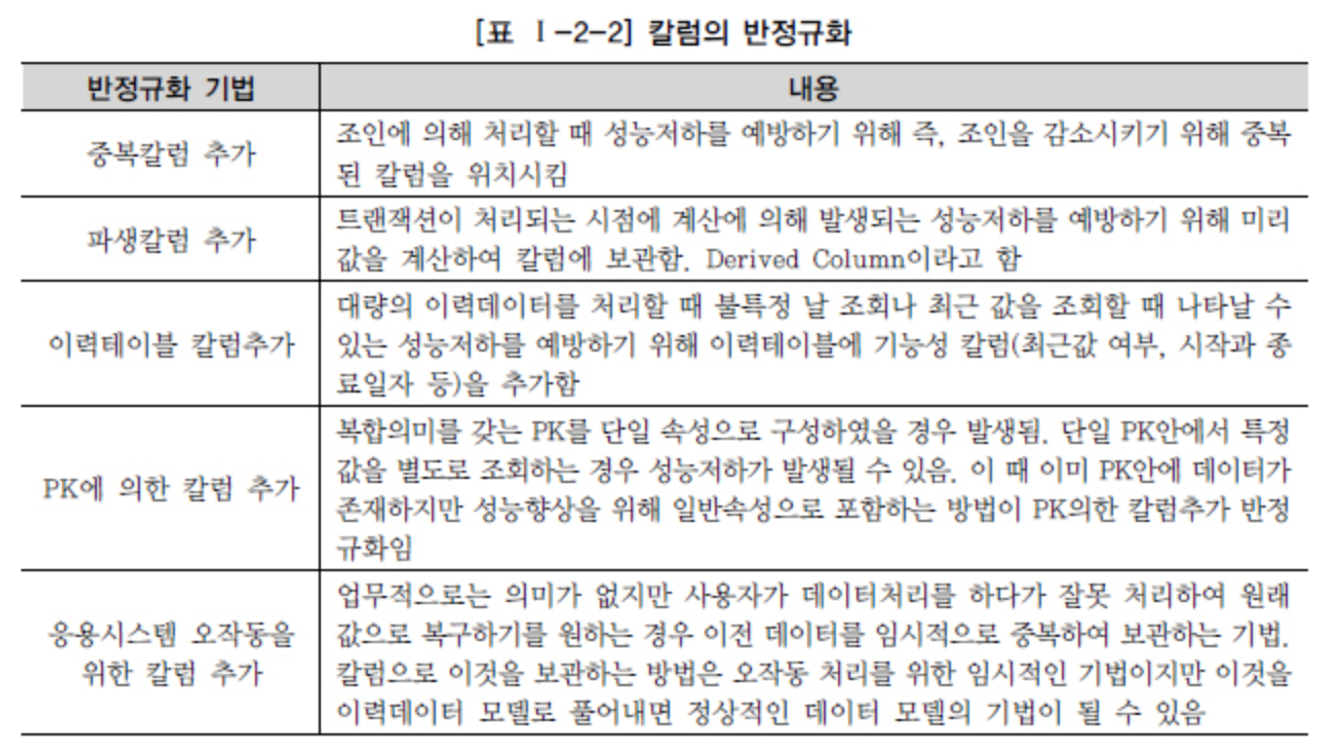
출처 DataOnAir - 반정규화와 성능

출처 - DataOnAir - 반정규화와 성능
2024년 4월 3일
2024년 4월 28일
2024년 4월 25일
2024년 4월 25일
2024년 11월 29일
2025년 3월 23일
댓글0