주제
- #논리적 데이터 모델링
- #데이터베이스
- #관계형 데이터 모델링
작성: 2024-04-09
작성: 2024-04-09 12:21
요구 사항 분석과 개념적 데이터 모델링에 비해, 논리적 데이터 모델링은 좀 더 기계적인 절차다.
맵핑 룰(Mapping Rule)을 기준으로 관계형 데이터베이스 패러다임에 맞도록 개념적 데이터 모델링 산출물인 ERD를 변환하는 과정이 주를 이룬다.
가장 먼저 FK가 없는 테이블이 우선적으로 표현하기 편하다.
1:1 관계에서는 두 테이블간에 의존 관계를 살펴보고 FK를 설정한다.
부모와 자식 테이블로 볼 수 있다.
1:N 관계에서는 1을 N이 참조하므로, N에 FK를 설정한다.
관계형 데이터베이스에서 N:M 관계를 처리하기 위해서는 중간 테이블(맵핑 테이블 또는 연결 테이블이라고도 한다)을 생성하여 표현한다.
이 때 중요한 점은, 맵핑 테이블을 기준으로 참조되는 양쪽 테이블의 카디널리티와 옵셔널리티를 표현 해주어야 한다.
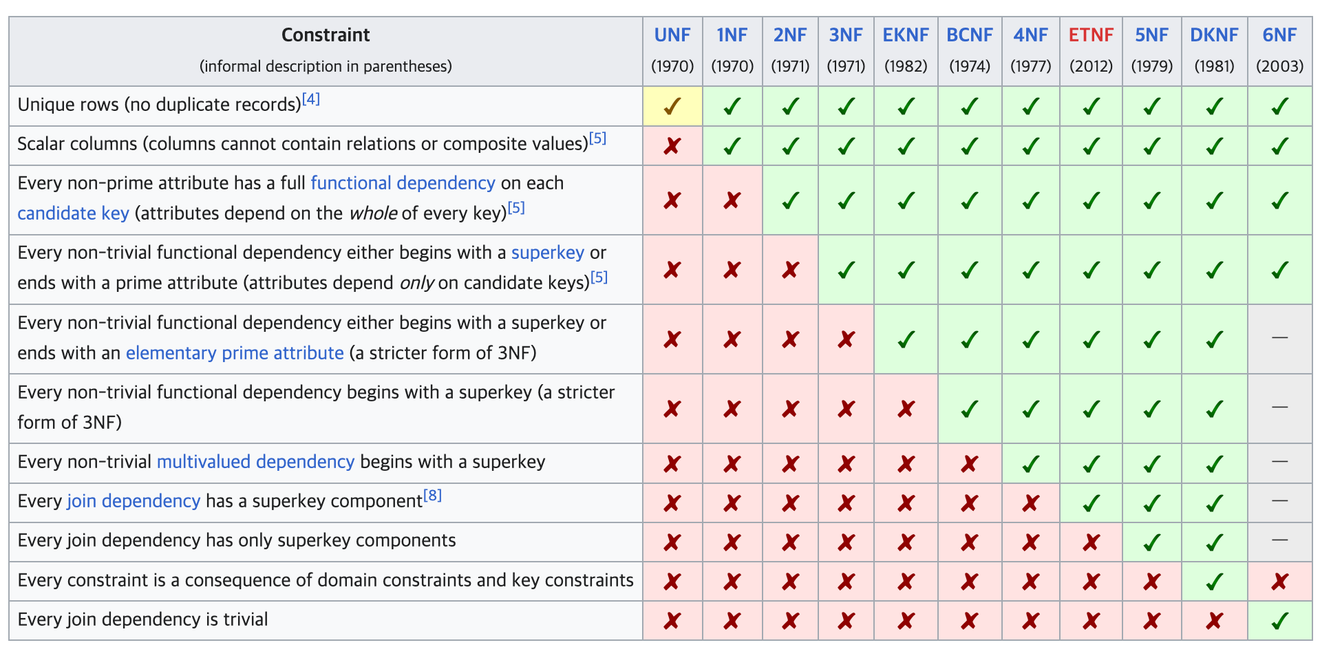
Wikipedia - Database Normalization
정제되지 않은 테이블을 관계형 데이터베이스에 어울리는 표로 만드는 과정이다.
산업적으로 사용되는 정규화 과정은 제 3 정규화 과정까지이며, 그 뒤의 정규화 과정들은 학술적으로 주로 이용된다.
정규화는 한번에 하나의 단계씩 순차적으로 진행해야한다.
제 1 정규화의 대원칙을 살펴보면, 무슨 말인지 이해하기 어렵지만 단순히 각 컬럼이 하나의 값만을 가져야 한다는 것이다.
만약 하나의 컬럼안에 여러 값이 들어있다면, 즉 원자적이지 않다면 SQL문으로 조인하기도 어렵고 여러가지 문제점을 일으킬 수 있다.
테이블의 행 중에 중복되는 값이 존재한다면, 해당 행이 의존하고 있는 컬럼을 찾아서 분리 한다.
이행적 종속성이라는 말이 굉장히 이해하기 어렵다. 이해한 바로는, 특정 테이블에서 암시적으로 다른 테이블의 식별자를 의미하는 값(물론 FK는 제외한다)이 하나 이상이라면 그것을 이행적 종속성이라고 하는 것 같다.
2024년 3월 29일
2024년 4월 3일
2024년 4월 28일
2024년 9월 7일
2024년 4월 28일
2024년 4월 28일
댓글0